
Using the "Chandrasekhar Recursions" for Likelihood Evaluation of DSGE Models
Keywords: Kalman filter, likelihood estimation, computational techniques
Abstract:
In likelihood-based estimation of linearized Dynamic Stochastic General Equilibrium (DSGE) models, the evaluation of the Kalman Filter dominates the running time of the entire algorithm. In this paper, we revisit a set of simple recursions known as the "Chandrasekhar Recursions" developed by Morf (1974) and Morf et al. (1974) for evaluating the likelihood of a Linear Gaussian State Space System. We show that DSGE models are ideally suited for the use of these recursions, which work best when the number of states is much greater than the number of observables. In several examples, we show that there are substantial benefits to using the recursions, with likelihood evaluation up to five times faster. This gain is especially pronounced in light of the trivial implementation costs - no model modification is required. Moreover, the algorithm is complementary with other approaches.
JEL Classification: C18, C63, E20
1 Introduction
Dynamic Stochastic General Equilibrium (DSGE) are increasingly estimated by Central Banks and academic economists. In estimation, the model equilibrium conditions can be linked to the data using a Linear Gaussian State Space (LGSS) representation. As model complexity increases, so too does computational time. In maximum likelihood and Bayesian contexts, the log likelihood has to be evaluated hundreds of thousands or millions of times, usually in sequential fashion. In this enviroment, likelihood computation time dominates the running time of the entire algorithm. So it becomes crucial to construct efficient algorithms for likelihood evaluation and state filtering. To wit, considerable effort has been expended constructing elaborate filters tailored to DSGE models-see, for example, Strid and Walentin (2009).
The purpose of this paper is to report an old and simple algorithm for fast likelihood evaluation outlined in Morf (1974) and Morf et al. (1974) and show that it is ideally suited for DSGE models. The method, which we will call the "Chandrasekhar Recursions" (CR), is simple to implement and can yield considerable speed improvements.
This paper is closely related to Strid and Walentin (2009), who develop a "Block Kalman Filter" by exploiting the a priori known structure of the DSGE model to avoid some large matrix calculations. The algorithm must be applied on a case-by-case basis. We compare the algorithms in the example section. Moreover, in principle, one could use the CR and also exploit the block structure of the DSGE model. Finally, although the CR has not been used to aid the estimation of DSGE models, they have been employed in a general time series context before; see, for example, Klein et al. (1998).
The paper is structured as follows. Section 2 contains background information on the DSGE models and the Kalman Filter, Section 3 contains the derivation of the Chandrasekhar Recursions, Section 4 contains four examples, and Section 5 concludes.
2 The Kalman Filter and DSGE Models
The starting point for our analysis is the LGSS representation of an economic model. The state vector ![]() is an
is an
![]() collection of all the relevant variables in the economic model, while
collection of all the relevant variables in the economic model, while
![]() is
is
![]() vector of structural shocks driving the model. The state equation 1 is derived by first linearizing and then solving the model; see An and Schorfheide (2007) for details.
vector of structural shocks driving the model. The state equation 1 is derived by first linearizing and then solving the model; see An and Schorfheide (2007) for details.
The vector ![]() is an
is an
![]() vector of observables, and
vector of observables, and ![]() is an
is an
![]() vector of measurement errors. This paper assumes that
vector of measurement errors. This paper assumes that
![]() for ease of exposition. The objects
for ease of exposition. The objects
![]() are matrix functions of a vector
are matrix functions of a vector ![]() of structure parameters. We
suppress the dependence for convenience. We make two assumptions, which are very often imposed in applications.
of structure parameters. We
suppress the dependence for convenience. We make two assumptions, which are very often imposed in applications.
- The system matrices
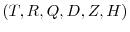 are time-invariant.
are time-invariant. - The process
 is stationary. This means that for our filtering problem, we can use the invariant distribution to initialize our state recursion.
is stationary. This means that for our filtering problem, we can use the invariant distribution to initialize our state recursion.
The goal of the econometrician is to evaluate the log likelihood
![]() where
where
![]() . This is accomplished by using the Kalman Filter. The Kalman Filter computes the log likelihood of the model using the predictive error decomposition,
. This is accomplished by using the Kalman Filter. The Kalman Filter computes the log likelihood of the model using the predictive error decomposition,
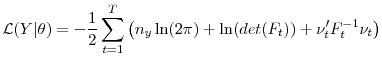
Where, the forecast error ![]() and the forecast error variance
and the forecast error variance ![]() are given
by,
are given
by,
The quantities
![]() and
and ![]() are the predictive state mean and variance,
are the predictive state mean and variance,
Equation 7 is often called the matrix Riccati difference equation because of its resemblance to the univariate Riccati differential equation. The initial conditionals
![]() and
and ![]() are, in principle, hyperparameters to be specified
(or estimated) by the user, but this algorithm will use the unconditional distribution. Then
are, in principle, hyperparameters to be specified
(or estimated) by the user, but this algorithm will use the unconditional distribution. Then
![]() and
and ![]() will be the unconditional variance, i.e., the
one that solves the discrete Lyapunov Equation,
will be the unconditional variance, i.e., the
one that solves the discrete Lyapunov Equation,
| (8) |
This gain is usually written as
![]() . Essentially it delivers the optimal extraction of information from the observations at time
. Essentially it delivers the optimal extraction of information from the observations at time ![]() .
.
We are interested in computing the likelihood, which we could do by iterating (in suitable order) over the above equations. However, this filtering procedure slows down as the number of states, ![]() , grows. In particular, the performance is dominated by the updating of the state variance using Riccati equation
, grows. In particular, the performance is dominated by the updating of the state variance using Riccati equation
![]() . In that equation, we must perform the matrix multiplication,
. In that equation, we must perform the matrix multiplication,
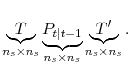
3 The Chandrasekhar Recursions
The essence of the Chandrasekhar Recursions is the avoidance of direct computation of ![]() by instead looking at the difference in the state
variances,
by instead looking at the difference in the state
variances,
Before discussing the recursions for ![]() and
and ![]() , it's worth noting that the
forecast error variance
, it's worth noting that the
forecast error variance ![]() ,
, ![]() and
and
![]() can be rewritten as recursions driven by
can be rewritten as recursions driven by
![]() .
.
For verification of these recursions, see the Appendix. The heart of the algorithm lies in the recursions for
| (12) |
This means we can write the initial difference of state variances as,
| (13) | |||
| (14) |
Note that thse equations already satistify the initial conditions, since F
Finally, we must derive the recursions for ![]() and
and ![]() . To do this, we
utilize the following Lemma. Lemma. For
. To do this, we
utilize the following Lemma. Lemma. For
![]() ,
,
| (15) |
Proof. See Appendix.
Thus, the Ricatti-type difference equation in ![]() is replaced by another difference equation in terms of
is replaced by another difference equation in terms of
![]() . In fact, this new difference equation gives the Chandrasekhar Recursion its name, because it evokes the "so-called Chandrasekhar algorithm through which the matrix
[Riccati Equation] is replaced by two coupled differential equations of lesser dimensionality Aknouche and Hamdi (2007)." Using the Lemma, substitute our decomposition
. In fact, this new difference equation gives the Chandrasekhar Recursion its name, because it evokes the "so-called Chandrasekhar algorithm through which the matrix
[Riccati Equation] is replaced by two coupled differential equations of lesser dimensionality Aknouche and Hamdi (2007)." Using the Lemma, substitute our decomposition
![]() for
for
![]() , to obtain
, to obtain
| (16) |
Rewriting with ![]() removed from the inner product, we have,
removed from the inner product, we have,
| (17) |
From here it is easy to see that we can rewrite
| (18) |
Where ![]() and
and ![]() follow the recursions,
follow the recursions,
Combining the equations in 19, with the rewritten recursions for ![]() and
and ![]() ,
,
These equations, used in conjunction with with Equations 4 and 6, can be used to iteratively compute the log likelihood in equation 3. We have elimated the state variance prediction, ![]() , from all the calculations in the algorithm and hence avoid the most computationally intensive calculation. Pseudo code is reported below.
, from all the calculations in the algorithm and hence avoid the most computationally intensive calculation. Pseudo code is reported below.
Initialization.
- Solve the Lyapunov Equation for
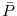
- Set
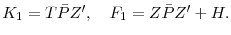
- Set
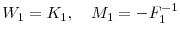 .
.
Iteration. For each time period
![]() .
.
- Compute
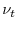 , and evaluate the likelihood.
, and evaluate the likelihood. - Compute
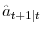 .
. - Compute
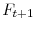 using Equation 20, and
using Equation 20, and
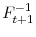 .
. - Compute
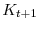 using Equation 21,
using Equation 21, - Compute
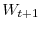 using part one of Equation 19.
using part one of Equation 19. - Compute
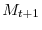 using part two of Equation 19.
using part two of Equation 19.
Another advantage of this initialization is that it can shown that ![]() will converge to a matrix as
will converge to a matrix as ![]() gets large. This is analgous to the steady state of the system expressed in usual form. With a general initialization, though, one cannot show that
gets large. This is analgous to the steady state of the system expressed in usual form. With a general initialization, though, one cannot show that ![]() will
converge to anything. Finally, note that we can recover
will
converge to anything. Finally, note that we can recover ![]() by
by
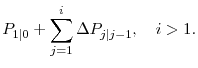
3.1 Discussion
It is difficult to compute analytically the exact speed gain given by the Chandrasekhar Recursions given the differences between highly optimized linear algebra routines across architectures. Still, one can perform a crude assessment of the differences in the algorithms without resorting to purely empirical studies. We looked at all the matrix multiplications, including intermediate calculations, in the Kalman Filter and the Chandrasekhar Recursions, taking care to avoid unnecessary calculations, to gain insight into the differences in the two algorithms.
Table 1 lists the remaining matrix multiplication operations after the "common" operations have been canceled out. The two algorithms appear almost the mirror image of one another, with ![]() and
and ![]() switched and a few additional operations for the Chandrasekhar recursions. Using naive linear algebraic calculations, the running time of two additional distinct
operations for the Kalman Filter is
switched and a few additional operations for the Chandrasekhar recursions. Using naive linear algebraic calculations, the running time of two additional distinct
operations for the Kalman Filter is ![]() and
and
![]() . For the Chandrasekhar Recursions, the running times are
. For the Chandrasekhar Recursions, the running times are
![]() and
and
![]() . It is clear that if
. It is clear that if
![]() , the Kalman Filter will have greater algorithmic complexity than the Chandrasekhar recursions. If
, the Kalman Filter will have greater algorithmic complexity than the Chandrasekhar recursions. If ![]() , the situation will be reversed.
, the situation will be reversed.
Given that DSGE models feature more states than observables, the Chandrasekhar recursions seem a promising algorithm on this basis. However, the calculations in Table 1 are based on (1) a crude matrix multiplication accounting and (2) the naive matrix multiplication algorithmic complexity. Moreover, we have abstracted from matrix addition and transposes. We use four examples to give empirical guidance on the relative performance.
4 Four Examples
We compare the algorithm using four different models: a small Real Business Cycle Model, the Generic State Space model of Chib and Ramamurthy (2010), the Smets and Wouters (2007) model and the model of Schmitt-Grohe and Uribe (2010). For each of the models, we calculate the "wall" (clock) time it takes to evaluate the likelihood at a particular point in the posterior 1000 times. We normalized these times, with the fastest algorithm being normalized to 100. This is a crude comparison, but it gives a sense of the actual user experience running the algorithms. We compare three algorithms, the standard Kalman Filter, the Block Kalman Filter of Strid and Walentin (2009), and the Chandrasekhar Recursions. We implement all the algorithms in Intel Fortran 11.1 and Matlab 2010a.
We wrote code for the standard KF and the CR recursions, and used the code provided by Strid and Walentin (2009) for the Block Kalman Filter. This algorithm, specific for DSGE models, uses a priori knowledge of the structure of ![]() - it has large matrix of zeros where the exogenous variables load onto the endogenous variables - and
- it has large matrix of zeros where the exogenous variables load onto the endogenous variables - and ![]() , which is often quite sparse, to build a fast Kalman filter. It requires the user to prestructure the model in a particular way and apply it on a case-by-case basis. We did not benchmark this for the Generic State Space model, since it is not a DSGE model.
, which is often quite sparse, to build a fast Kalman filter. It requires the user to prestructure the model in a particular way and apply it on a case-by-case basis. We did not benchmark this for the Generic State Space model, since it is not a DSGE model.
The Fortran code utilizes Intel's Math Kernel Library implementation of BLAS and LAPACK fast linear algebra routines, including dsymm, symmetric matrix multiplication. The Matlab code uses a standard distribution of BLAS and does not consider symmetric matrix multiplication, which might disadvantage it somewhat. Both programs utilize multithreaded BLAS, using four threads for matrix operations.4 All calculations were on a 12-core Intel Xeon x5670 CPU (2.93GHz) with L1, L2, and L3 cache sizes of 32K, 256K, 12288K, respectively.
One other technical detail worth mentioning is method of computing the solution to the discrete Lyapunov Equation. For the Chandrasekhar Recursions, it is crucial that this solution be (at least approximately) correct. Repeating trials suggests that for large (![]() greater than 100), the Matlab routine dlyap does not provide a good solution. Instead, the Matlab implementation of the CR uses lyap_symm, distributed as part of Dynare Adjemian et
al. (2011), which yields a much better solution.
greater than 100), the Matlab routine dlyap does not provide a good solution. Instead, the Matlab implementation of the CR uses lyap_symm, distributed as part of Dynare Adjemian et
al. (2011), which yields a much better solution.
The equilibriums for the RBC and SW models are computed with Sims (2002) GENSYS. GENSYS is widely used to compute equilibriums of Linear Rational Expectations Models in economics. The algorithm uses the Generalized (complex) Schur decomposition, which gives it the advantage that "controls" and "states" don't have to be specified ahead of time; i.e., redundant states can be included. This means that for our examples, it is possible to reduce the size of the state vector and thus the efficacy of the CR. Given that our examples are of the small and medium size, we think that they are illustrative of speed gains for larger models.
4.1 Real Business Cycle Model
The first example is a simple Real Business Cycle model. There are ![]() observables, labor and output. In the GENSYS formulation of the model, there are
observables, labor and output. In the GENSYS formulation of the model, there are ![]() states. The model is driven by two shocks, neutral technology and demand.
states. The model is driven by two shocks, neutral technology and demand.
Table 2 reports the timings associated with evaluating the likelihood 1000 times, with the fastest normalized to 100. The language gain associated with Fortran is substantial, with the likelihood evaluation between four and 8 times faster than their Matlab counterparts. Within languages, that the Chandrasekhar recursions are the fastest in both languages. While, the Block KF outperforms the standard KF in Matlab, that is not the case in Fortran. The slow performance in Fortran is consistent with the findings of Strid and Walentin (2009), who find that the additional overhead associated with the increased number of matrix multiplications outweighs the size gain for small models.
4.2 Generic State Space Model
The next example is the Generic State Space model used in Chib and Ramamurthy (2010). This is not a DSGE model. It has no meaningful economic interpretation. It is, however, a good example, because there are fewer states than observables. In
the model ![]() while
while ![]() . Stochastic singularity is avoided by
measurement error. The data used is simulated, with length 200 periods.
. Stochastic singularity is avoided by
measurement error. The data used is simulated, with length 200 periods.
Table 3 shows the timings associated with evaluating the likelihood 1000 times, with the fastest normalized to 100.5 The language gain is quite substantial, with Fortran being roughly four times faster for both algorithms. This large difference is mostly driven by the length of sample size. Concentrating on within-language performance, we see that there is a slight drop in speed when using the CR in Fortran. Relative to the standard KF, the CR about 17% percent slower. On the other hand, they are about 10% faster in Matlab. In both cases, the speed difference is small compared to the other examples.
4.3 Smets-Wouters Model
The Smets and Wouters (2007) is a medium-scale macroeconomic model that has become a benchmark for many issues related to the estimation and identification of DSGE models. In this formulation of the model, there are ![]() states and only
states and only ![]() observables.6 This example includes some redundant states, I but it is consistent with the conventional way of writing and estimating such models in economics. 50 states are not unusual for a medium-scale DSGE model, especially the kind used in central banks. For this reason, this example serves as a good benchmark.
observables.6 This example includes some redundant states, I but it is consistent with the conventional way of writing and estimating such models in economics. 50 states are not unusual for a medium-scale DSGE model, especially the kind used in central banks. For this reason, this example serves as a good benchmark.
Table 4 reports the timings associated with evaluating the likelihood 1000 times, with the fastest normalized to 100. It quite apparent that the language gain associated with Fortran relative Matlab is large, with the running time approximately doubled for each algorithm in Matlab compared to Fortran. Within a language, we see that the Chandrasekhar Recursions dominate both the Block and the standard KF. For Matlab, the CR offer algorithmic speed gains of 61% and 72%, for the Block KF and Standard KF respectively.
This speed gain is accomplished by eliminating of the matrix operation
![]() . Indeed, inspection of the Matlab Profiler indicates that this operation is about 45% of all filtering time for the Standard KF. For the Block KF, about 35% of the filtering
time is spent on similar, slightly smaller matrix multiplication corresponding to the non-exogenous sub-state vector (which has
. Indeed, inspection of the Matlab Profiler indicates that this operation is about 45% of all filtering time for the Standard KF. For the Block KF, about 35% of the filtering
time is spent on similar, slightly smaller matrix multiplication corresponding to the non-exogenous sub-state vector (which has
![]() states.)
states.)
4.4 Schmitt-Grohe and Uribe (2010) Model
The final model comes from Schmitt-Grohe and Uribe (2010). The paper estimates a DSGE model augmented with "news" shocks. Specifically, they construct a real business cycle model with investment adjustment consts, capacity utilization, habits, and Jaimovich and Rebelo (2009) preferences. Each of the seven structural shocks is driven by three innovations. One of these innovations is unanticipated, while the other two are anticipated four and quarters ahead, respectively. The process for a given exogenous shock,
![]() , looks like:
, looks like:
Table 4 reports the timings associated with evaluating the likelihood 1000 times, with the fastest normalized to 100. Once again, the gain from using Fortran is substantial, regardless of the algorithm used. Once again, the Chandrasekhar Recursions dominate the Kalman Filter irrespective of
language. Much like the Smets-Wouters model, much of the gain comes from eliminating the matrix operation
![]() . Overall, the CR posts algorithmic gains of about 38% and 68% for Matlab and Fortran, respectively.
. Overall, the CR posts algorithmic gains of about 38% and 68% for Matlab and Fortran, respectively.
5 Conclusion
For DSGE models, the biggest bottleneck in computation is the evaluation of the log likelihood. Within this evaluation, the prediction of the state variance is the slowest operation, taking about half of all filtering time for large models. This paper has presented the Chandrasekhar recursions, a simple, fast algorithm for evaluating the likelihood of a Linear Gaussian State Space System. The CR algorithm works by eliminating the predicted state variance from the Kalman Filter equations altogether. In this way, it is ideally suited for DSGE models. The price paid to use this algorithm is relatively small. The system must be stationary and time invariant, assumptions that are typically satisfied for DSGE models.
It should be noted that this method is entirely consistent with other fast filtering techniques, such as Durbin and Koopman (2000). These additional speed gains are largely orthogonal to the ones presented here. Given the ease of implementation and apparent speed gains, the Chandrasekhar Recursions should become part of applied macroeconomists' computational toolkit.
Bibliography
7.2 Verification of the difference equation for
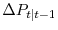 .
.
To show that Chandrasekhar recursions work for the special case discussed above, we show how to write the recursions for ![]() and
and ![]() in terms of
in terms of
![]() .
.
Proof. Using the definition of ![]() and adding and subtracting
and adding and subtracting ![]() , A similar algebraic manipulation can be used for
, A similar algebraic manipulation can be used for ![]() . Note that we can also write
. Note that we can also write ![]() as
as
Proof of Lemma. From the Kalman Filter, we have that
Note that we can write the final product in the equation, using 23, 20, and tediously expanding terms, as,