
Sequential Monte Carlo Sampling for DSGE Models
Abstract:
JEL CLASSIFICATION: C11, C15, E10
KEY WORDS: Bayesian analysis, DSGE models, monte carlo methods, parallel computing
1 Introduction
Bayesian methods are now widely used to estimate dynamic stochastic general equilibrium (DSGE) models. Bayesian methods combine the likelihood function of a DSGE model with a prior distribution for its parameters to form a posterior distribution that can then be used for inference and decision making. Because it is infeasible to compute moments of the posterior distribution analytically, simulation methods must be used to characterize the posterior. Starting with Schorfheide (2000) and Otrok (2001), the random walk Metropolis-Hastings (RWMH) algorithm - an iterative simulation technique belonging to the class of algorithms known as Markov chain Monte Carlo (MCMC) algorithms - has been the workhorse simulator for DSGE models. Herbst (2011) reports that 95% of papers published from 2005 to 2010 in eight top economics journals use the RWMH algorithm to implement Bayesian estimation of DSGE models.
While the complexity of DSGE models has increased over time, the efficacy of the RWMH algorithm has declined. It is well documented, e.g., Chib and Ramamurthy (2010) and Herbst (2011), that the sequences of DSGE model parameter draws generated by the RWMH algorithm can be very slow to converge to the posterior distribution. This problem is not limited to DSGE model applications; it is important for many areas of applied Bayesian research. Parameter draws may exhibit high serial correlation such that averages of these draws converge very slowly to moments of posterior distributions, or the algorithm may get stuck near local mode and fail to explore the posterior distribution in its entirety (see, for instance, Neal (2003)).
In this paper, we explore an alternative class of algorithms, namely, so-called sequential Monte Carlo (SMC) algorithms, to generate draws from posterior distributions associated with DSGE models. SMC techniques are typically used for solving intractable integration problems (such as filtering
nonlinear state space systems); however, they can be used to estimate static model parameters - a point raised by Chopin (2002). The SMC method employed here amounts to recursively constructing importance samplers for a sequence of distributions that begin at an easy-to-sample initial
distribution and end at the posterior, supplemented by a series of intermediate "bridge" distributions. The draws from these distributions are called particles and each particle is associated with an importance weight. The particles that represent bridge distribution ![]() are "mutated" into particles for bridge distribution
are "mutated" into particles for bridge distribution ![]() using the Metropolis-Hastings (MH)
algorithm.
using the Metropolis-Hastings (MH)
algorithm.
The contributions of this paper are threefold. First, we tailor a generic SMC algorithm to make it suitable for the analysis of a large-scale DSGE model. More specifically, building on insights from the application of RWMH algorithms to DSGE models, we use random blocking of parameters as well
as mixture proposal distributions during the MH mutation step of the algorithm. Without these modifications, the algorithm failed to explore the posterior surface of large-scale DSGE models. We also made the proposal distribution adaptive, that is, its mean and covariance matrix in iteration
![]() is a function of the particles generated in iteration
is a function of the particles generated in iteration ![]() . Second, we present a
strong law of large numbers (SLLN) and a central limit theorem (CLT) for the specific version of our algorithm. In particular, we show that, under some regularity conditions, the adaptive determination of the proposal distribution in the mutation step of our algorithm does not affect the limit
distribution of the SMC approximation of posterior moments.
. Second, we present a
strong law of large numbers (SLLN) and a central limit theorem (CLT) for the specific version of our algorithm. In particular, we show that, under some regularity conditions, the adaptive determination of the proposal distribution in the mutation step of our algorithm does not affect the limit
distribution of the SMC approximation of posterior moments.
Third, we provide two empirical illustrations involving large-scale DSGE models, namely the widely used Smets and Wouters (2007) model (hereafter SW model) and a DSGE model with anticipated (news) shocks developed by Schmitt-Grohe and Uribe (2012) (hereafter SGU model). We find that the SMC algorithm is more stable than the RWMH algorithm if applied repeatedly to generate draws from the same posterior distribution, providing a better approximation of multimodal posterior distributions, in particular. We estimate the SW model under the prior used by Smets and Wouters (2007) as well as a more diffuse prior. While the fit of the model, measured by the marginal data density, substantially improves under the diffuse prior, the posterior surface becomes multimodal and the standard RWMH algorithm does a poor job in capturing this multimodality. We also introduce a small modification to the prior distribution used by SGU to estimate their news shock model and find that conclusions about the importance of news shocks for business cycles can change dramatically. While SGU report that anticipated shocks explain about 70% of the variance of hours worked, under our slightly modified prior the posterior distribution becomes bimodal and most of the posterior probability concentrates near the mode that implies that the contribution of anticipated shocks to hours is only 30%. The RWMH algorithm is unable to characterize this multimodal posterior reliably.
We build on several strands of the existing literature. There exists an extensive body of work in the statistical literature on applying SMC methods to posterior inference for static model parameters as in Chopin (2002). Textbook treatments can be found in Cappe and Moulines, and Ryden (2005) and Liu (2008) and a recent survey is provided by Creal (2012). The theoretical analysis in our paper builds heavily on Chopin (2004), by modifying his proofs to suit our particular version of the SMC algorithm. So far as we know, ours is the second paper that uses SMC to implement Bayesian inference in DSGE models. Creal (2007) presents a basic algorithm, which he applies to the small-scale DSGE model of Rabanal and Rubio-Ramirez (2005). While we used his algorithm as a starting point, the application to large-scale DSGE models required substantial modifications including the more elaborate adaptive mutation step described above as well as a different sequence of bridge distributions. Moreover, our implementation exploits parallel computation to substantially speed up the algorithm, which is necessary for the practical implementation of this algorithm on modern DSGE models.
In complementary research,Durham and Geweke (2012) use an SMC algorithm to estimate an EGARCH model as well as several other small-scale reduced-form time series models. They employ a graphical processing unit (GPU) to implement an SMC algorithm using the predictive likelihood distribution as the bridge distribution. For our applications, the use of GPUs appeared impractical because the solution and likelihood evaluation of DSGE models involves high-dimensional matrix operations that are not readily available in current GPU programming languages. Durham and Geweke (2012) also propose an adaptive tuning scheme for the sequence of the bridge distributions and the proposal distributions used in the particle mutation step. They suggest determining the tuning parameters in a preliminary run of the SMC algorithm to ensure that the adaptive tuning scheme does not invalidate the CLT for the SMC approximation. Our theoretical analysis suggests that this is unnecessary, provided that the tuning scheme satisfies certain regularity conditions. The authors propose a version of the SMC algorithm that divides particles into groups and carries out independent computations for each group. The variation across groups provides a measure of numerical accuracy. By running the SMC multiple times, we employ an evaluation scheme in our paper that is similar in spirit to theirs.
Other authors have explored alternatives to the version of the RWMH algorithm that has become standard in DSGE model applications. Several papers that have tried to improve upon the RWMH, including Chib and Ramamurthy (2010), Curdia and Reis (2010), Kohn, Giordani, and Strid (2010), and Herbst (2011). These papers propose alternative MCMC algorithms that improve upon the standard single-block RWMH algorithm by grouping parameters into blocks and cycling over conditional posterior distributions (the so-called Metropolis-within-Gibbs algorithm) and by changing the proposal distribution that is used to generate proposed draws in the Metropolis steps. Each of these algorithms, however, is an MCMC technique and remains to some extent susceptible to the above criticism of highly correlated draws.
On the computational front, multiple processor and core environments are becoming more readily available. While likelihood evaluation routines and MCMC algorithms can be written to take advantage of this,1 neither is "embarrassingly parallelizable," that is, neither naturally exploits the parallel computing framework. This computational challenge might bias researchers to simulate too few draws in their MCMC chains, exacerbating the statistical problem discussed above. SMC algorithms, on the other hand, can easily take advantage of a parallel processing environment. In the extreme case, each draw (or particle) from the initial distribution can be assigned to a separate processor and then converted into a sequence of draws from the "bridge" distributions. While, some communication between the processors is necessary to normalize the particle weights and to potentially eliminate particle degeneracy by a re-sampling step, but the most time-consuming task-namely the evaluation of the likelihood function-can be executed in parallel.
The remainder of this paper is organized as follows. In Section 2, we review some basic insights underlying SMC methods. The SMC algorithm tailored to DSGE model applications is presented in Section 3 and its theoretical properties are studied in Section 4. Section 5 contains three numerical illustrations, one pertaining to a stylized state space model, to motivate estimation problems inherent to DSGE models, and two based on DSGE model posteriors obtained from actual U.S. data. Section 6 concludes. The proofs for Section 4 and a detailed description of the DSGE models estimated in Section 5 as well as additional empirical results are relegated to the Online Appendix.
2 Sequential Monte Carlo Methods
Let ![]() denote the likelihood function and
denote the likelihood function and ![]() the prior density.
The object of interest is the posterior density
the prior density.
The object of interest is the posterior density ![]() given by
given by

While for linearized DSGE models with Gaussian innovations and a regular prior density the function
One of the important steps in all SMC algorithms involves importance sampling: we might try to approximate ![]() using a different, tractable density
using a different, tractable density ![]() that is easy to sample from. Importance sampling is based on the identity
that is easy to sample from. Importance sampling is based on the identity
![\begin{displaymath} E_{\pi}[h(\theta)] = \int h(\theta) \pi(\theta) d\theta = \frac{1}{Z} \int_{\Theta}h(\theta)w(\theta)g(\theta)d\theta, \quad \mbox{where} \quad w(\theta) = \frac{f(\theta)}{g(\theta)}, \end{displaymath}](img18.gif)
converges almost surely (a.s.) to

Importance sampling was first used for posterior inference in DSGE models by DeJong, Ingram, and Whiteman (2000). However, in practice, it is extremely difficult to find densities ![]() that lead to
efficient importance samplers. This task is particularly challenging if the posterior has a non-normal shape, containing several peaks and valleys. The essence of the SMC methods employed in this paper is to construct sequential particle approximations to intermediate distributions, indexed by
that lead to
efficient importance samplers. This task is particularly challenging if the posterior has a non-normal shape, containing several peaks and valleys. The essence of the SMC methods employed in this paper is to construct sequential particle approximations to intermediate distributions, indexed by
![]() :2
:2
![\begin{displaymath} \pi_n(\theta) = \frac{f_{n}(\theta)}{Z_n} = \frac{[p(Y\vert\theta)]^{\phi_{n}}p(\theta)} {\int[p(Y\vert\theta)]^{\phi_{n}}p(\theta)d\theta}, \quad n=1, \ldots, \phi_{N_\phi} \end{displaymath}](img37.gif)
3 An SMC Algorithm for DSGE Models
We begin with the description of the basic algorithm in Section 3.1. This algorithm consists of three steps, using Chopin (2004)'s terminology: correction, that is, reweighting the particles to reflect the density in iteration ![]() ; selection, that is, eliminating any particle degeneracy by resampling the particles; and mutation, that is, propagating the particles forward using a Markov transition kernel to adapt to
the current bridge density. Section 3.2 provides details on the choice of the transition kernel in the mutation step, and the adaptive choice of various tuning parameters is discussed in Section 3.3. Finally, we provide a
summary of the key aspects of our algorithm in Section 3.4.
; selection, that is, eliminating any particle degeneracy by resampling the particles; and mutation, that is, propagating the particles forward using a Markov transition kernel to adapt to
the current bridge density. Section 3.2 provides details on the choice of the transition kernel in the mutation step, and the adaptive choice of various tuning parameters is discussed in Section 3.3. Finally, we provide a
summary of the key aspects of our algorithm in Section 3.4.
3.1 The Basic Algorithm
To avoid confusion as to whether ![]() is drawn from
is drawn from ![]() or
or
![]() , we equip the parameter vector with a subscript
, we equip the parameter vector with a subscript ![]() . Thus,
. Thus, ![]() is associated with the density
is associated with the density ![]() .
.
- Initialization. (
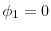 ). Draw the initial particles from the prior:
). Draw the initial particles from the prior:
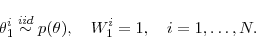
- Recursion. For
 ,
,
- Correction. Reweight the particles from stage
 by defining the incremental and normalized weights
by defining the incremental and normalized weights
![\begin{displaymath} \tilde w_{n}^{i} = [p(Y\vert\theta^{i}_{n-1})]^{\phi_{n} - \phi_{n-1}}, \quad \tilde{W}^{i}_{n} = \frac{\tilde w_n^{i} W^{i}_{n-1}}{\frac{1}{N} \sum_{i=1}^N \tilde w_n^{i} W^{i}_{n-1}}, \quad i = 1,\ldots,N. \end{displaymath}](img50.gif)
An approximation of![\mathbb{E}_{\pi_n}[h(\theta)]](img51.gif) is given by
is given by
- Selection. Compute the effective sample size
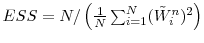 .
.
Case (i): If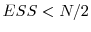 , resample the particles via multinomial resampling. Let
, resample the particles via multinomial resampling. Let
 denote
denote 
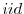 draws from a multinomial distribution characterized by support points and weights
draws from a multinomial distribution characterized by support points and weights
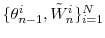 and set
and set 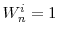 . Case (ii): If
. Case (ii): If
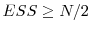 , let
, let
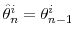 and
and
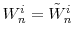 ,
, 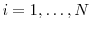 . An approximation of
is given by
. An approximation of
is given by
- Mutation. Propagate the particles
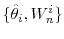 via
via 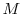 steps of a MH algorithm with transition density
steps of a MH algorithm with transition density
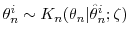 and stationary distribution
and stationary distribution 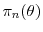 (see Algorithm 2 for details below). An approximation of
is given by
(see Algorithm 2 for details below). An approximation of
is given by
- Correction. Reweight the particles from stage
- For
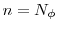 (
(
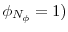 the final importance sampling approximation of
the final importance sampling approximation of
![\mathbb{E}_\pi[h(\theta)]](img71.gif) is given by:
is given by:
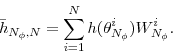
(9)
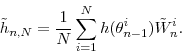
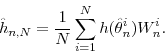
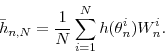
Our basic SMC algorithm requires tuning in two dimensions. First, the user has to specify the number of particles ![]() . Under suitable regularity conditions discussed in Section 4, the SMC approximations of posterior moments satisfy a CLT, which implies that the precision (i.e. inverse variance) of the approximation increases in proportion to
. Under suitable regularity conditions discussed in Section 4, the SMC approximations of posterior moments satisfy a CLT, which implies that the precision (i.e. inverse variance) of the approximation increases in proportion to ![]() .
Second, the user has to determine the tempering schedule
.
Second, the user has to determine the tempering schedule
![]() . All other things equal, increasing the number of stages of the tempering schedule,
. All other things equal, increasing the number of stages of the tempering schedule, ![]() , will decrease the distance between bridge distributions and thus make it easier to maintain particle weights that are close to being uniform. The cost of increasing
, will decrease the distance between bridge distributions and thus make it easier to maintain particle weights that are close to being uniform. The cost of increasing ![]() is that each stage requires additional likelihood evaluations. To control the shape of the tempering schedule, we introduce a parameter
is that each stage requires additional likelihood evaluations. To control the shape of the tempering schedule, we introduce a parameter ![]() :
:
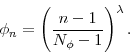
A large value of
Algorithm 1 is initialized by generating ![]()
![]() draws
from the prior distribution. This initialization will work well as long as the prior is sufficiently diffuse to assign non-trivial probability mass to the area of the parameter space in which the likelihood function peaks.3 If the particles are initialized based on a more general distribution with density
draws
from the prior distribution. This initialization will work well as long as the prior is sufficiently diffuse to assign non-trivial probability mass to the area of the parameter space in which the likelihood function peaks.3 If the particles are initialized based on a more general distribution with density ![]() , then for
, then for ![]() the incremental weights have to be corrected by the ratio
the incremental weights have to be corrected by the ratio
![]() . In the selection step, the resampling is only executed if the effective sample size
. In the selection step, the resampling is only executed if the effective sample size ![]() , which is a function of the variance of the particle weights, falls below some threshold. We discuss the rationale for this threshold rule in more detail in Section 4.
, which is a function of the variance of the particle weights, falls below some threshold. We discuss the rationale for this threshold rule in more detail in Section 4.
3.2 The Transition Kernel for the Mutation Step
The transition kernel
![]() is generated through a sequence of
is generated through a sequence of ![]() Metropolis-Hastings steps. It is indexed by a vector of tuning parameters
Metropolis-Hastings steps. It is indexed by a vector of tuning parameters ![]() . The transition kernel is constructed such that for each
. The transition kernel is constructed such that for each ![]() the posterior
the posterior ![]() is an invariant distribution. The MH steps are summarized in the following algorithm. Let
is an invariant distribution. The MH steps are summarized in the following algorithm. Let ![]() denote a particular set of values for the parameter vector
denote a particular set of values for the parameter vector ![]() and
and ![]() be a covariance matrix that is conformable with the parameter vector
be a covariance matrix that is conformable with the parameter vector ![]() . In
Section 3.3 we will replace
. In
Section 3.3 we will replace ![]() and
and ![]() by estimates of
by estimates of
![]() and
and
![]() .
.
- Randomly partition4 the parameter vector
 into
into  equally sized blocks, denoted by
equally sized blocks, denoted by 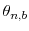 ,
,
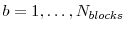 . Moreover, let
. Moreover, let 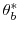 and
and 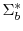 be the partitions of
be the partitions of 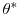 and
and 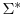 that correspond to the subvector .
that correspond to the subvector . - For each particle
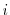 , run steps of the following MH algorithm. For
, run steps of the following MH algorithm. For 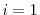 to :
to :
For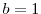 to :
to :
- Let
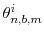 be the parameter value for
be the parameter value for
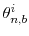 in the
in the 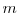 -th iteration (initialization for
-th iteration (initialization for 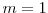 :
:
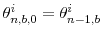 ) and let
) and let
![\theta^i_{n,-b,m} = \big[ \theta^i_{n,1,m},\ldots, \theta^i_{n,b-1,m}, \theta^i_{n,b+1,m-1},\ldots, \theta^i_{n,N_{blocks},m-1} \big]](img105.gif) .
. - Generate a proposal draw
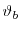 from the mixture distribution
from the mixture distribution
and denote the density of the proposal distribution by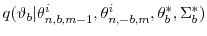 .
. - Define the acceptance probability
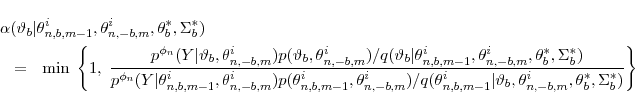
and let
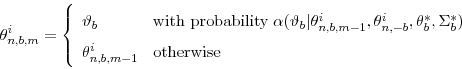
- Let
- Let
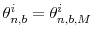 for
.
for
.
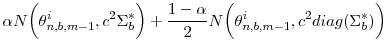
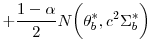
The particle-mutation algorithm uses several insights from the application of RWMH algorithms to DSGE models. First, Chib and Ramamurthy (2010) have documented that in DSGE model applications, blocking of parameters can dramatically reduce the persistence in Markov chains generated by
the MH algorithm. ![]() determines the number of partitions of the parameter vector. For simple models with elliptical posteriors, blocking the parameter vector is unnecessary. When the
posterior becomes complex or the dimensionality of the parameter vector is large, however, moving all the parameters in a single block precludes all but the smallest moves, which could hamper the mutation step. Second, Kohn, Giordani, and Strid (2010) have proposed an adaptive MH algorithm for DSGE model posteriors
in which the proposal density is a mixture of a random-walk proposal, an independence proposal, and a
determines the number of partitions of the parameter vector. For simple models with elliptical posteriors, blocking the parameter vector is unnecessary. When the
posterior becomes complex or the dimensionality of the parameter vector is large, however, moving all the parameters in a single block precludes all but the smallest moves, which could hamper the mutation step. Second, Kohn, Giordani, and Strid (2010) have proposed an adaptive MH algorithm for DSGE model posteriors
in which the proposal density is a mixture of a random-walk proposal, an independence proposal, and a ![]() -copula estimated from previous draws of the chain. Adopting this general idea, our
proposal density in Step 2(a) of Algorithm 2 is also a mixture. The first component corresponds to a random-walk proposal with non-diagonal covariance matrix, the second component is a random-walk proposal with diagonal covariance matrix, and the third component is
an independence proposal density.
-copula estimated from previous draws of the chain. Adopting this general idea, our
proposal density in Step 2(a) of Algorithm 2 is also a mixture. The first component corresponds to a random-walk proposal with non-diagonal covariance matrix, the second component is a random-walk proposal with diagonal covariance matrix, and the third component is
an independence proposal density.
The tuning parameter
![]() controls the weight of the mixture components. The parameter
controls the weight of the mixture components. The parameter ![]() scales the covariance matrices of the proposal densities.5 The number of MH steps
scales the covariance matrices of the proposal densities.5 The number of MH steps ![]() affects the probability that the particle mutation step is successful in the sense that
affects the probability that the particle mutation step is successful in the sense that
![]() . In practice, the effect of increasing
. In practice, the effect of increasing ![]() turned
out to be similar to the effect of raising
turned
out to be similar to the effect of raising ![]() and thereby reducing the distance between bridge distributions. In the applications in Section 5, we
set
and thereby reducing the distance between bridge distributions. In the applications in Section 5, we
set ![]() .
.
3.3 Adaption of the Transition Kernel
To achieve a good performance of the SMC algorithm, it is important to choose some of the tuning parameters adaptively, that is, tuning parameters for iteration ![]() are chosen based on the
particles generated in iteration
are chosen based on the
particles generated in iteration ![]() . We collect the adaptively chosen parameters in the vector
. We collect the adaptively chosen parameters in the vector ![]() :
:
where
- Compute importance sampling approximations
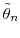 and
and
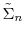 of
of
![\mathbb{E}_{\pi_n}[\theta]](img88.gif) and
and
![\mathbb{V}_{\pi_n}[\theta]](img89.gif) based on the particles
.
based on the particles
. - Compute the average empirical rejection rates
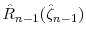 , based on the Mutation step in iteration . The
averages are computed across the blocks and across the three mixture components separately.
, based on the Mutation step in iteration . The
averages are computed across the blocks and across the three mixture components separately. - Adjust the scaling factor according to
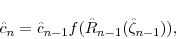
where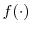 is given by
is given by
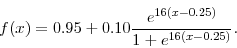
- Execute Algorithm 2 by replacing
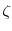 with
with
![\hat{\zeta}_n = \big[ \hat{c}_{n}, \tilde{\theta}_n, vech(\tilde{\Sigma}_n)' \big]'](img132.gif) .
.
Note that ![]() , which means that the scaling factor stays constant whenever the target acceptance rate is achieved. If the acceptance rate is below (above) 25% the scaling factor is
decreased (increased). To satisfy the regularity conditions for the theoretical analysis in Section 4, we chose a function
, which means that the scaling factor stays constant whenever the target acceptance rate is achieved. If the acceptance rate is below (above) 25% the scaling factor is
decreased (increased). To satisfy the regularity conditions for the theoretical analysis in Section 4, we chose a function ![]() that is differentiable.
that is differentiable.
3.4 Further Discussion
Our implementation of the SMC algorithm differs from that in Creal (2007) in two important dimensions. First, our mutation step is more elaborate. The mixture proposal distribution proved to be important for adapting the algorithm to large-scale DSGE models with complicated multimodal
posterior surfaces. The random blocking scheme is important for avoiding bad blocks as the correlation structure of the tempered posterior changes. Moreover, the introduction of the tempering parameter, ![]() , is crucial. Creal (2007) uses a linear cooling schedule (i.e.,
, is crucial. Creal (2007) uses a linear cooling schedule (i.e., ![]() ). Even for a large number of stages (
). Even for a large number of stages (![]() ) at
) at ![]() , the information contained in
, the information contained in
![]() dominates the information contained in the prior. This means that initializing the algorithm from the prior is impractical, as sample impoverishment occurs
immediately. In light of this, Creal (2007) initializes the simulator from a student-
dominates the information contained in the prior. This means that initializing the algorithm from the prior is impractical, as sample impoverishment occurs
immediately. In light of this, Creal (2007) initializes the simulator from a student-![]() distribution centered at the posterior mode. The initialization presumes prior knowledge of the
mode(s) of the posterior and is not well suited in applications where there are many modes or the posterior is severely non-elliptical. Instead, by using a
distribution centered at the posterior mode. The initialization presumes prior knowledge of the
mode(s) of the posterior and is not well suited in applications where there are many modes or the posterior is severely non-elliptical. Instead, by using a ![]() , we are able to add
information from the likelihood to the prior slowly. This allows us to initialize the algorithm from the prior, working without presupposition about the shape of the posterior. Collectively, these additional tuning parameters yield a degree of flexibility that is crucial for the implementation of
SMC algorithms on large-scale DSGE models.
, we are able to add
information from the likelihood to the prior slowly. This allows us to initialize the algorithm from the prior, working without presupposition about the shape of the posterior. Collectively, these additional tuning parameters yield a degree of flexibility that is crucial for the implementation of
SMC algorithms on large-scale DSGE models.
Second, our implementation exploits parallel computing to substantially speed up the algorithm. The potential for parallelisation is a key advantage of SMC over MCMC routines. In Algorithm 2, step 2 involves
![]() MH steps. Here, the principal computational bottleneck is the evaluation of the likelihood itself.7 The total number of likelihood evaluations in the SMC algorithm is equal to
MH steps. Here, the principal computational bottleneck is the evaluation of the likelihood itself.7 The total number of likelihood evaluations in the SMC algorithm is equal to
![]() . For some of the examples considered in this paper, that number can be in the tens of millions. In our experience, the standard number of draws in
an MCMC estimation of a DSGE model is rarely more than one million. So it would appear that the SMC algorithm would take a prohibitively long time to run. With SMC methods, however, one can exploit the fact that the
. For some of the examples considered in this paper, that number can be in the tens of millions. In our experience, the standard number of draws in
an MCMC estimation of a DSGE model is rarely more than one million. So it would appear that the SMC algorithm would take a prohibitively long time to run. With SMC methods, however, one can exploit the fact that the
![]() likelihood evaluations in Step 2 of Algorithm 2 can be executed independently for each of the
likelihood evaluations in Step 2 of Algorithm 2 can be executed independently for each of the ![]() particles. Given access to a multiple processor8 environment, this feature is very
useful. Because multiple core/processor setups are quite common, parallelization can be achieved easily in many programming languages, e.g., via the MATLAB command parfor, even on a single machine.
particles. Given access to a multiple processor8 environment, this feature is very
useful. Because multiple core/processor setups are quite common, parallelization can be achieved easily in many programming languages, e.g., via the MATLAB command parfor, even on a single machine.
In our implementation, we use multiple machines (distributed memory) communicating via a Message Passing Interface (MPI). To get a sense of gains from parallelization, let ![]() be the
running time of an algorithm using
be the
running time of an algorithm using ![]() processors. The relative speedup is given by
processors. The relative speedup is given by
![]() . For example, for the standard SW model in Section 5.2,
. For example, for the standard SW model in Section 5.2,
![]() , which means that using 24 processors speeds up the algorithm by a
factor of 15. A back-of-the-envelope calculation suggests that, for the specific model and computational setup used here, about 97% of the SMC algorithm's time is spent in Step 2 of
Algorithm 2. This means that parallelization is extremely efficient.9
, which means that using 24 processors speeds up the algorithm by a
factor of 15. A back-of-the-envelope calculation suggests that, for the specific model and computational setup used here, about 97% of the SMC algorithm's time is spent in Step 2 of
Algorithm 2. This means that parallelization is extremely efficient.9
4 Theoretical Properties
We proceed with a formal analysis of Algorithm 1 and provide some regularity conditions under which the SMC approximations satisfy a SLLN and CLT. The main results are summarized in four theorems. The first three theorems establish a SLLN/CLT for the correction,
selection, and mutation steps of Algorithm 1. The fourth theorem shows that the adaptive choice of the transition kernel discussed in Section 3.3 does not, under some regularity conditions, affect the asymptotic variance of the SMC
approximation. The first three theorems (and their proofs) essentially correspond to Lemmas A.1, A.2, and A.3 in Chopin (2004). We make three modifications: (i) while our proofs closely follow the proofs in Chopin (2004), we use our specific assumptions about the prior and
likelihood function; (ii) our algorithm executes the three steps in a different order; and (iii) we resample only if ESS falls below the threshold ![]() , which requires an adjustment in some of
the asymptotic variance formulas. Although the first three theorems are not new, we think that it is worthwhile to reproduce them, because the asymptotic variance formulas provide valuable insights for practitioners into the behavior of the algorithm. To the best of our knowledge, the fourth
theorem is new. It states that the adaptive choice of
, which requires an adjustment in some of
the asymptotic variance formulas. Although the first three theorems are not new, we think that it is worthwhile to reproduce them, because the asymptotic variance formulas provide valuable insights for practitioners into the behavior of the algorithm. To the best of our knowledge, the fourth
theorem is new. It states that the adaptive choice of ![]() has no effect on the limit distribution of the SMC approximation. This asymptotic variance, of course, depends on
has no effect on the limit distribution of the SMC approximation. This asymptotic variance, of course, depends on ![]() , which we define to be the probability limit of
, which we define to be the probability limit of ![]() in (12). Detailed proofs of the four theorems are provided in the Online Appendix. We begin with some assumptions on the prior and the likelihood function:10
in (12). Detailed proofs of the four theorems are provided in the Online Appendix. We begin with some assumptions on the prior and the likelihood function:10
For the analysis of a DSGE model, the restriction to proper prior distributions does not pose a real constraint on the researcher. In fact, most priors used in the literature are fairly informative and many parameters have a bounded domain. We also assume that the likelihood function is bounded
from above and that there exists a set of parameters with non-zero measure under the prior distribution for which the likelihood function is strictly positive, meaning that the marginal tempered data density is positive at the observed data. Throughout this section, we will assume that the object
of interest is the posterior mean of the scalar function ![]() . Extensions to vector-valued functions are straightforward. The convergence of the sequential Monte Carlo approximations
requires the existence of moments. We define the classes of functions
. Extensions to vector-valued functions are straightforward. The convergence of the sequential Monte Carlo approximations
requires the existence of moments. We define the classes of functions ![]() and
and ![]() as
as
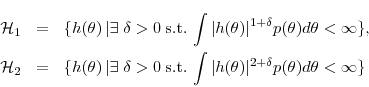
and our convergence results will apply to functions in these two classes. Assumption 1 implies that for functions in
We follow Chopin (2004) and state the convergence results in an inductive manner, starting from the following assumption:
- (i)
-
![\bar{h}_{n-1,N} \stackrel{a.s.}{\longrightarrow} \mathbb{E}_{\pi_{n-1}}[h]](img163.gif) for every
for every
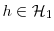 .
. - (ii)
-
![\sqrt{N} ( \bar{h}_{n-1,N} - \mathbb{E}_{\pi_{n-1}}[h] ) \Longrightarrow N(0,\Omega_{n-1}(h))](img165.gif) for every
for every
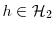 .
.
It is straightforward to verify that Assumption 2 is satisfied for ![]() . Recall that
. Recall that ![]() . According to Step 1 of Algorithm 1, the particles
. According to Step 1 of Algorithm 1, the particles
![]() are obtained using an
are obtained using an ![]() sample from the prior distribution.
Thus, for
sample from the prior distribution.
Thus, for
![]() and
and
![]() , the moment conditions for the SLLN and the CLT for
, the moment conditions for the SLLN and the CLT for ![]() random
variables are satisfied and
random
variables are satisfied and
![]() . To present the subsequent results, it is convenient to normalize the incremental weights as follows. Let
. To present the subsequent results, it is convenient to normalize the incremental weights as follows. Let
such that
The asymptotic variance
![]() has the familiar form of the variance of an importance sampling approximation where the
has the familiar form of the variance of an importance sampling approximation where the ![]() s correspond to the importance sampling weights. As discussed, for instance, in Liu (2008), a crude approximation of
s correspond to the importance sampling weights. As discussed, for instance, in Liu (2008), a crude approximation of
![]() is given by
is given by
![]() , which provides a rationale for monitoring
, which provides a rationale for monitoring ![]() (see the selection step of Algorithm 1).12 However,
(see the selection step of Algorithm 1).12 However, ![]() does not directly measure the overall asymptotic variance of the SMC approximation. For the subsequent selection step, we distinguish between the case in which the particles are resampled, i.e.
does not directly measure the overall asymptotic variance of the SMC approximation. For the subsequent selection step, we distinguish between the case in which the particles are resampled, i.e. ![]() , and the case in which the resampling is skipped.
, and the case in which the resampling is skipped.
A comparison of
![]() in cases (a) and (b) highlights that the resampling adds noise
in cases (a) and (b) highlights that the resampling adds noise
![]() to the Monte Carlo approximation. However, it also equalizes the particle weights and thereby reduces the variance in the correction step of iteration
to the Monte Carlo approximation. However, it also equalizes the particle weights and thereby reduces the variance in the correction step of iteration ![]() . The rule of resampling whenever
. The rule of resampling whenever ![]() tries to strike a balance between this
trade-off. To obtain the convergence results for the mutation step, we need the following additional assumption on the transition kernel:
tries to strike a balance between this
trade-off. To obtain the convergence results for the mutation step, we need the following additional assumption on the transition kernel:
![\begin{eqnarray*} \lefteqn{ \mathbb{E}\big[ W^2 \mathbb{V}_{K_n(\cdot\vert\theta;\zeta)}[h] \big] } \ &=& \int_{\theta_{n-1}} \cdots \int_{\theta_{n-p}} \mathbb{V}_{K_n(\cdot\vert\theta_{n-1};\zeta)}[h] \left( \prod_{l=1}^p v^2_{n+1-l}(\theta_{n-l}) \right)\left( \prod_{l=1}^{p-1} K_{n-l}(\theta_{n-l}\vert\theta_{n-l-1};\zeta) \right) \ && \times \pi_{n-p}(\theta_{n-p}) d\theta_{n-p} \cdots d\theta_{n-1}. \end{eqnarray*}](img194.gif)
The asymptotic variance ![]() consists of two terms. The first term captures the average conditional variance of the Markov transition kernel
consists of two terms. The first term captures the average conditional variance of the Markov transition kernel
![]() . If the particle weights are not equal to one, then the conditional variance needs to be scaled by the weights, which are functions of the particles from the
previous iterations. The second term captures the variance of the average of the conditional expectations
. If the particle weights are not equal to one, then the conditional variance needs to be scaled by the weights, which are functions of the particles from the
previous iterations. The second term captures the variance of the average of the conditional expectations
![]() , which are functions of the resampled particles
, which are functions of the resampled particles
![]() . The variance
. The variance ![]() depends on the tuning parameter
depends on the tuning parameter
![]() of the Markov transition kernel.
of the Markov transition kernel.
To study the effect of choosing the tuning parameters ![]() adaptively by replacing it with
adaptively by replacing it with ![]() , where
, where ![]() is measurable with respect to the
is measurable with respect to the ![]() -algebra generated by
-algebra generated by
![]() , we use the following decomposition
, we use the following decomposition
- (iii)
-
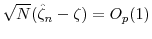
- (iv)
-
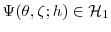 and
and
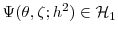 are twice differentiable and there exist constants
are twice differentiable and there exist constants  and
and  , independent of
, independent of 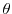 and , such that
and , such that
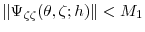 and
and
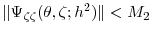 .
.
Since
![]() for all
for all ![]() , it is also the
case that the expected values of the derivatives with respect to
, it is also the
case that the expected values of the derivatives with respect to ![]() are equal to zero:
are equal to zero:
![]() and
and
![]() The proof relies on the insight that
The proof relies on the insight that
![\begin{eqnarray*} \frac{1}{\sqrt{N}} \sum_{i=1}^N \big( \mathbb{E}_{K_n(\cdot\vert\hat{\theta}_n^i;\hat{\zeta}_n)}[h] - \mathbb{E}_{K_n(\cdot\vert\hat{\theta}_n^i;\zeta)}[h] \big) &=& \left( \frac{1}{N} \sum_{i=1}^N \Psi_\zeta(\hat{\theta}_n^i,\zeta;h) W_n^i \right) \sqrt{N}(\hat{\zeta}_n - \zeta) + o_p(1) \ &=& o_p(1) O_p(1) + o_p(1). \end{eqnarray*}](img213.gif)
The first
Example: Suppose that ![]() ,
, ![]() , and
, and ![]() . The transition density can be expressed as
. The transition density can be expressed as
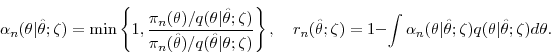
The function
Under the restriction
Its derivatives are given by
The derivatives of the log density with respect to
We now verify that
![]() is stochastically bounded. Let
is stochastically bounded. Let
![]() and define
and define
![]() as the Monte Carlo approximation of
as the Monte Carlo approximation of ![]() based on the
particles
based on the
particles
![]() . Then, Theorem 1 implies that
. Then, Theorem 1 implies that
![]() . The empirical rejection rate in iteration
. The empirical rejection rate in iteration ![]() is given by
is given by
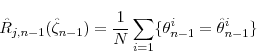
and has expected value
![\begin{displaymath} \mathbb{E}[\hat{R}_{j,n-1}(\hat{\zeta}_{n-1})\vert\hat{F}_{n-1,N}] = \frac{1}{N} \sum_{i=1}^N r_{n-1}(\hat{\theta}_{n-1}^i; \hat{\zeta}_{n-1}). \end{displaymath}](img237.gif)
The arguments used in the proof of Theorem 3 can be modified to verify that conditional on
Verifying the regularity conditions for the general transition kernel associated with Algorithm 2 is more tedious. For ![]() or
or ![]() , the representation of the transition kernel's density in (14) involves additional point masses and the expression for
, the representation of the transition kernel's density in (14) involves additional point masses and the expression for
![]() in (15) becomes more complicated. For
in (15) becomes more complicated. For ![]() , it is no longer true that the conditional acceptance probability
, it is no longer true that the conditional acceptance probability
![]() is invariant to
is invariant to ![]() . Due to the
. Due to the
![]() operator in the definition of
operator in the definition of
![]() , there are points at which the function is no longer differentiable with respect to
, there are points at which the function is no longer differentiable with respect to ![]() . Thus, rather than verifying the differentiability of the integrants in (15) directly one has to integrate with respect to
. Thus, rather than verifying the differentiability of the integrants in (15) directly one has to integrate with respect to ![]() separately over the regions
separately over the regions
![]() and
and
![]() and show that the boundary
and show that the boundary
![]() is a smooth function of
is a smooth function of ![]() .
.
5 Applications
We now consider three applications of the proposed SMC algorithm and provide comparisons to a standard RWMH algorithm. Section 5.1 evaluates the posterior distribution of a small stylized state-space model based on simulated data. In Section 5.2 we consider the SW model. Typically, the SW model is estimated under a fairly informative prior distribution that leads to a well-behaved posterior distribution when combined with U.S. data. However, under a less informative prior the posterior distribution becomes more irregular and provides an interesting application for our algorithm. Finally, in Section 5.3 we apply the algorithm to a real business cycle model proposed by Schmitt-Grohe and Uribe (2012) which, in addition to standard shocks, is driven by a large number of anticipated shocks, e.g., news about future changes in technology. These news shocks make parameter identification more difficult. The SW model and the SGU model are estimated based on actual U.S. data.
5.1 A Stylized State-Space Model
To illustrate the difficulties that can arise when generating draws from the posterior density ![]() , consider the following stylized state-space model discussed in Schorfheide (2010):
, consider the following stylized state-space model discussed in Schorfheide (2010):
![\begin{displaymath} y_t = [1~ 1]s_t, \quad s_t = \left[\begin{array}{cc}\phi_1 & 0 \\ \phi_3 & \phi_2\end{array}\right]s_{t-1} + \left[\begin{array}{c} 1 \ 0\end{array}\right]\epsilon_t, \quad \epsilon_t \sim iid N(0,1). \end{displaymath}](img252.gif)
The first state,
![Figure 1: State Space Model: Log Likelihood Function and Posterior Draws. Figure 1: State Space Model: Log Likelihood Function and Posterior Draws. Two
Panels. The left panel plots a likelihood contour plot for the state space
model. It has two peaks, one at roughly [0.4, 0.7] and the second at [0.9,
0.3]. Overlayed on this figure is a scatterplot with draws from the RWMH and
SMC algorithm. The SMC algorithm covers both modes, while the RWMH does not.
The right panel plots a sequence of estimates of the probability density
functions for theta_1 are as function of the cooling parameter phi. When phi =
0, the density estimate is very close to uniform. As phi gets larger, the
density becomes bimodal, clearly the correct shape.](figure1.gif)
Notes: The left panel shows a contour plot of the log likelihood function overlaid with draws from the RWMH (red) and SMC (red) algorithms. The right panel shows sequential density estimates of πn (θ1) using output from the SMC algorithm. Here n = 1, φ...,50, φ1 = 0, and φ 50= 1.
simulate ![]() observations given
observations given
![]() . This parameterization is observationally equivalent to
. This parameterization is observationally equivalent to
![]() . Moreover, we use a prior distribution that is uniform on the square
. Moreover, we use a prior distribution that is uniform on the square
![]() and
and
![]() .
.
Tuning of Algorithms. The SMC algorithm is configured as follows. We set ![]() ,
, ![]() , and
, and ![]() . Since this is a very simple (and correctly specified) model, we use only
. Since this is a very simple (and correctly specified) model, we use only ![]() block,
block, ![]() , and set
, and set ![]() . The
SMC algorithm works extremely well for this small problem, so changing the hyperparameters does not change the results or running time very much. For comparison, we also run the standard RWMH algorithm with a proposal density that is a bivariate independent normal scaled to achieve a 25% acceptance
rate. Changing this proposal variance does not materially affect the results.
. The
SMC algorithm works extremely well for this small problem, so changing the hyperparameters does not change the results or running time very much. For comparison, we also run the standard RWMH algorithm with a proposal density that is a bivariate independent normal scaled to achieve a 25% acceptance
rate. Changing this proposal variance does not materially affect the results.
Results. The left panel of Figure 1 plots the contours of the posterior density overlaid with draws from the SMC algorithm (black) and the RWMH (red). It
is clear that the RWMH algorithm fails to mix on both modes, while the SMC does a good job of capturing the structure of the posterior. To understand the evolution of the particles in the SMC algorithm, in the right panel of Figure 1 we show estimates of the sequence of (marginal) densities
![]() , where
, where
![]() and
and
![]() . The density for
. The density for ![]() starts out very flat, reflecting the
fact that for low
starts out very flat, reflecting the
fact that for low ![]() the uniform prior dominates the scaled likelihood. As
the uniform prior dominates the scaled likelihood. As ![]() increases,
the bimodal structure quickly emerges and becomes very pronounced as
increases,
the bimodal structure quickly emerges and becomes very pronounced as ![]() approaches one. This plot highlights some of the crucial features of SMC. The general characteristics of the
posterior are established relatively quickly in the algorithm. For larger DSGE models, this feature will guide our choice set
approaches one. This plot highlights some of the crucial features of SMC. The general characteristics of the
posterior are established relatively quickly in the algorithm. For larger DSGE models, this feature will guide our choice set ![]() , as the early approximations are crucial for the
success of the algorithm. As the algorithm proceeds, the approximation at step
, as the early approximations are crucial for the
success of the algorithm. As the algorithm proceeds, the approximation at step ![]() provides a good importance sample for the distribution at step
provides a good importance sample for the distribution at step ![]() .
.
5.2 The Smets-Wouters Model
The SW model is a medium-scale macroeconomic model that has become an important benchmark in the DSGE model literature. The model is typically estimated with data on output, consumption, investment, hours, wages, inflation, and interest rates. The details of the model, which we take exactly as presented in SW, are summarized in the Online Appendix. In our subsequent analysis, we consider two prior distributions. The first prior, which we refer to as the standard prior, is the one used by SW and many of the authors that build on their work. Our second prior is less informative than SW's prior and we will refer to it as the diffuse prior. However, the second prior is still proper.
Comparison Among Algorithms. We compute posterior moments based on our proposed SMC algorithm as well as a standard RWMH algorithm. To assess the precision of the Monte Carlo approximations, we run both algorithms 20 times and compute means and standard deviations of posterior moment
estimates across runs. To the extent that the number of particles is large enough for the CLTs presented in Section 4 to be accurate, the standard deviations reported below for the SMC can be interpreted as simulation approximations of the asymptotic variance (for
![]() ) that appears in Theorem 3. We have taken some care to ensure an "apples-to-apples" comparison by constraining the processing time to be roughly the
same across algorithms. Given our choice of tuning parameters (see below), the SMC algorithm for the SW model with the standard prior (diffuse prior), runs about 1 hour and 40 minutes (2 hours and 30 minutes) using two twelve-core Intel Xeon X5670 CPUs (24 processors in total) in parallel. The code
is written in Fortran 95 and uses the distributed-memory communication interface MPI.
) that appears in Theorem 3. We have taken some care to ensure an "apples-to-apples" comparison by constraining the processing time to be roughly the
same across algorithms. Given our choice of tuning parameters (see below), the SMC algorithm for the SW model with the standard prior (diffuse prior), runs about 1 hour and 40 minutes (2 hours and 30 minutes) using two twelve-core Intel Xeon X5670 CPUs (24 processors in total) in parallel. The code
is written in Fortran 95 and uses the distributed-memory communication interface MPI.
When comparing the SMC and RWMH algorithms, it is important to avoid giving the SMC algorithm an advantage simply because it can more easily exploit parallel programming techniques. In principle, we could instead run 24 copies of the RWMH on separate processor cores and merge the results
afterwards. This may reduce sampling variance if each of the RWMH chains has reliably converged to the posterior distribution. However, if there is a bias in the chains - because of, say, the failure to mix on a mode in a multimodal posterior or simply a slowly converging chain - then merging
chains will not eliminate that bias. Moreover, choosing the length of the "burn-in" phase may become an issue as discussed in Rosenthal (2000). Instead, we use a poor-man's parallelization of the RWMH algorithm. It is possible to parallelize MH algorithms via pre-fetching as discussed in
Strid (2009). Pre-fetching tries to anticipate the points in the parameter space that the MH algorithm is likely to visit in the next ![]() iterations and executes the likelihood evaluation
for these parameter values in parallel. Once the likelihood values have been computed one can quickly determine the next
iterations and executes the likelihood evaluation
for these parameter values in parallel. Once the likelihood values have been computed one can quickly determine the next ![]() draws. While coding the parallel MCMC algorithm efficiently is quite
difficult, the simulation results reported in Strid (2009) suggest that a parallelization using 24 processors would lead to a speedup factor of eight at best. Thus, in our poor-man's parallelization, we simply increase the running time of the RWMH algorithm on a single CPU by a factor of eight.
This results in approximately 10 million draws.
draws. While coding the parallel MCMC algorithm efficiently is quite
difficult, the simulation results reported in Strid (2009) suggest that a parallelization using 24 processors would lead to a speedup factor of eight at best. Thus, in our poor-man's parallelization, we simply increase the running time of the RWMH algorithm on a single CPU by a factor of eight.
This results in approximately 10 million draws.
Tuning of Algorithms. The hyperparameters of the SMC algorithm for the estimation under the standard prior are ![]() ,
,
![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() . The total product of the number of particles, stages, and blocks was chosen by the desired run time of the algorithm. The choice of
. The total product of the number of particles, stages, and blocks was chosen by the desired run time of the algorithm. The choice of ![]() at 500 was somewhat
arbitrary, but it ensured that the bridge distributions were never too "different." The parameter
at 500 was somewhat
arbitrary, but it ensured that the bridge distributions were never too "different." The parameter ![]() was calibrated by examining the correction step at
was calibrated by examining the correction step at ![]() . Essentially, we increased
. Essentially, we increased ![]() until the effective sample size after adding the first piece of information
from the likelihood was at least
until the effective sample size after adding the first piece of information
from the likelihood was at least ![]() ; roughly speaking, 80% of the initial particles retained substantial weight. We settled on the number of blocks by examining the behavior of the
adaptive scaling parameter
; roughly speaking, 80% of the initial particles retained substantial weight. We settled on the number of blocks by examining the behavior of the
adaptive scaling parameter ![]() in a preliminary run. Setting
in a preliminary run. Setting
![]() ensured that the proposal variances were never scaled down too much for sufficient mutation. For the estimation under the diffuse prior, we increase the number of blocks to
ensured that the proposal variances were never scaled down too much for sufficient mutation. For the estimation under the diffuse prior, we increase the number of blocks to
![]() . For the RWMH algorithm, we scale the proposal covariance to achieve an acceptance rate of approximately 30% over 5 million draws after a burn-in period of 5 million. Each RWMH chain was initialized with a draw from the prior distribution.
. For the RWMH algorithm, we scale the proposal covariance to achieve an acceptance rate of approximately 30% over 5 million draws after a burn-in period of 5 million. Each RWMH chain was initialized with a draw from the prior distribution.
Results from the Standard Prior. It turns out that with the standard prior, the results for the RWMH algorithm and the SMC algorithm are close, both for the posterior means and for the 5% and 95% quantiles of the posterior distribution. The Online Appendix contains a table
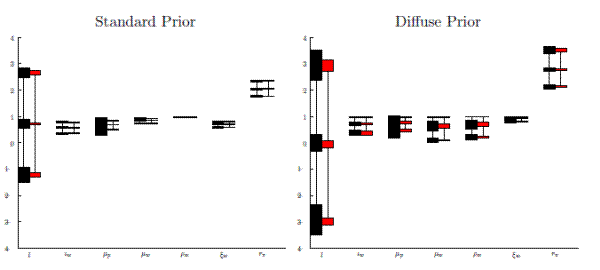
Notes: This Figure shows estimates of the mean, 5th and 95th percentile for the RWMH (black) and SMC (red) simulators for the SW model under the standard prior (left) and diffuse prior (right). The boxes are centered at the mean estimate (across 20 simulations) for each statistic while the shaded region shows plus and minus two standard deviations around this mean.
with posterior means as well as 90% equal-tail-probability credible intervals obtained from the two algorithms. A visual comparison of the RWMH and SMC algorithm under the standard prior is provided in the left panel of Figure 2. For seven selected parameters, Figure 2 presents the estimates of the mean, 5th, and 95th percentiles of the posterior distribution. The shaded region covers plus and minus two standard deviations (across runs) around the point estimates for each of the three statistics. The RWMH estimates are shown in black, while the SMC estimates are in red. The figure shows that both simulators are capturing the distribution, although the SMC algorithm is more precise, as indicated by the size of the red boxes relative to the black ones.The parameter where this difference is most stark is ![]() , which is the moving average term in the exogenous ARMA(1,1) price-markup shock process. For
, which is the moving average term in the exogenous ARMA(1,1) price-markup shock process. For ![]() , the black boxes representing the noise around estimates of the mean, 5th, and 95th percentiles overlap, which indicates substantial convergence problems. A close inspection of the output from the posterior simulators
shows the reason for this. On two of the twenty runs for the RWMH algorithm, the simulator becomes trapped in a region with relatively low posterior density. That is, there is a local mode on which the RWMH gets stuck. Note that this mode is small, so that it can be safely ignored when
characterizing the posterior distribution, unlike the multimodal posterior distributions seen below. Perhaps most
, the black boxes representing the noise around estimates of the mean, 5th, and 95th percentiles overlap, which indicates substantial convergence problems. A close inspection of the output from the posterior simulators
shows the reason for this. On two of the twenty runs for the RWMH algorithm, the simulator becomes trapped in a region with relatively low posterior density. That is, there is a local mode on which the RWMH gets stuck. Note that this mode is small, so that it can be safely ignored when
characterizing the posterior distribution, unlike the multimodal posterior distributions seen below. Perhaps most
| Algorithm (Method) | MEAN(Log MDD) | STD(Log MDD) |
| Standard Prior: SMC (Particle Estimate) | -901.739 | 0.33 |
| Standard Prior: RWMH (Modified Harmonic Mean) | -902.626 | 2.34 |
| Diffuse Prior: SMC (Particle Estimate) | -873.46 | 0.24 |
| Diffuse Prior: RWMH (Modified Harmonic Mean) | -874.56 | 1.20 |
disturbing is that output from these simulators "looks" fine, in the sense that there are no abrupt shifts in acceptance rates, recursive means, or other summary statistics routinely used as indications of convergence. The SMC algorithm easily avoids getting trapped in the vicinity of this mode, as the relatively small weight on particles in this region ensures they are dropped during a resampling step or mutated.
In addition to the posterior distribution of the parameters, the so-called marginal data density (MDD)
![]() plays an important role in DSGE model applications, because it determines the posterior model probability. The MDD is the normalization constant
that appears in the denominator of (1) and as constant
plays an important role in DSGE model applications, because it determines the posterior model probability. The MDD is the normalization constant
that appears in the denominator of (1) and as constant ![]() in (2). The top panel of Table 1 shows estimates of the marginal data densities (MDD) associated with the posterior simulators. While the SMC algorithm delivers an estimate of the MDD as a by-product of the simulation,
for the RWMH an auxiliary estimator must be used. We use the modified harmonic mean estimator of Geweke (1999). The estimates in Table 1 indicate that the SMC algorithm is
a more stable estimator of the MDD. The high standard deviation of the RWMH-based estimate is driven by the two runs that get stuck in a local mode. These runs produce MDD estimates of about -902.6, a much worse fit relative to the SMC algorithm.
in (2). The top panel of Table 1 shows estimates of the marginal data densities (MDD) associated with the posterior simulators. While the SMC algorithm delivers an estimate of the MDD as a by-product of the simulation,
for the RWMH an auxiliary estimator must be used. We use the modified harmonic mean estimator of Geweke (1999). The estimates in Table 1 indicate that the SMC algorithm is
a more stable estimator of the MDD. The high standard deviation of the RWMH-based estimate is driven by the two runs that get stuck in a local mode. These runs produce MDD estimates of about -902.6, a much worse fit relative to the SMC algorithm.
The Diffuse Prior. Some researchers argue that the prior distributions used by SW are implausibly tight, in the sense that they seem hard to rationalize based on information independent of the information in the estimation sample. For instance, the tight prior on the steady-state inflation rate is unlikely to reflect a priori beliefs of someone who has seen macroeconomic data only from the 1950s and 1960s. At the same time, this prior has a strong influence on the empirical performance of the model, as discussed in Del Negro and Schorfheide (2013). Closely related, Muller (2011) derives an analytical approximation for the sensitivity of posterior means to shifts in prior means and finds evidence that the stickiness of prices and wages is driven substantially by the priors.
One side benefit of tight prior distributions is that they tend to smooth out the posterior surface by down-weighting areas of the parameter space that exhibit local peaks in the likelihood function but are deemed unlikely under the prior distribution. Moreover, if the likelihood function contains hardly any information about certain parameters and is essentially flat with respect to these parameters, tight priors induce curvature in the posterior. In both cases, the prior information stabilizes the posterior computations. For simulators such as the RWMH this is crucial, as they work best when the posterior is well-behaved. With a view toward comparing the effectiveness of the different posterior simulators, we relax the priors on the SW model substantially. For parameters which previously had a Beta prior distribution, we now use a uniform distribution. Moreover, we scale the prior variances of the other parameters by a factor of three - with the exception that we leave the priors for the shock standard deviations unchanged. A table with the full specification of the prior is available in the Online Appendix.
| SMC:Parameter | SMC: Mean | [0.05, 0.95] | SMC: STD(Mean) | SMC: Neff | RWMH: Mean | [0.05, 0.95] | RWMH: STD(Mean) | Neff |
| 3.06 | [ 1.40, 5.26] | 0.04 | 1058 | 3.04 | [ 1.41, 5.14] | 0.15 | 60 | |
| -0.06 | [-2.99, 2.92] | 0.07 | 732 | -0.01 | [-2.92, 2.93] | 0.16 | 177 | |
| 0.11 | [ 0.01, 0.29] | 0.00 | 637 | 0.12 | [ 0.01, 0.29] | 0.02 | 19 | |
| 0.70 | [ 0.59, 0.78] | 0.00 | 522 | 0.69 | [ 0.58, 0.78] | 0.03 | 5 | |
| 1.71 | [ 1.50, 1.94] | 0.01 | 514 | 1.69 | [ 1.48, 1.91] | 0.04 | 10 | |
| 2.78 | [ 2.12, 3.52] | 0.02 | 507 | 2.76 | [ 2.11, 3.51] | 0.03 | 159 | |
| 0.19 | [ 0.03, 0.44] | 0.01 | 440 | 0.21 | [ 0.03, 0.48] | 0.08 | 3 | |
| 8.12 | [ 4.27, 12.59] | 0.16 | 266 | 7.98 | [ 4.16, 12.50] | 1.03 | 6 | |
| 0.14 | [ 0.09, 0.23] | 0.00 | 126 | 0.15 | [ 0.11, 0.20] | 0.04 | 1 | |
| 0.72 | [ 0.60, 0.82] | 0.01 | 91 | 0.73 | [ 0.62, 0.82] | 0.03 | 5 | |
| 0.73 | [ 0.37, 0.97] | 0.02 | 87 | 0.72 | [ 0.39, 0.96] | 0.03 | 36 | |
| 0.77 | [ 0.47, 0.98] | 0.02 | 77 | 0.80 | [ 0.54, 0.96] | 0.10 | 3 | |
| 0.69 | [ 0.21, 0.99] | 0.04 | 49 | 0.69 | [ 0.21, 0.99] | 0.09 | 11 | |
| 0.63 | [ 0.09, 0.97] | 0.05 | 49 | 0.63 | [ 0.09, 0.98] | 0.09 | 11 | |
| 0.93 | [ 0.80, 0.99] | 0.01 | 43 | 0.93 | [0.82, 0.99] | 0.02 | 8 |
Notes: Means and standard deviations are over 20 runs for each algorithm. The RWMH algorithms use 10 million draws with the first 5 million discarded. The SMC algorithms use 12,000 particles and 500 stages. The two algorithms utilize approximately the same computational resources. We
define
![]() .
.
Results from the Diffuse Prior. Table 2 summarizes the output of the posterior simulators under the diffuse prior, focusing on parameters for which the
standard deviation (STD) of the posterior mean approximation under the RWMH algorithm is greater than 0.02 (the results for the remaining parameters are reproduced in the Online Appendix). While the average estimated mean of the posterior seems to be roughly the same across the algorithms, the
variance across simulations is substantially higher under the RWMH algorithm. For instance, the standard deviation of the estimate of the mean for ![]() , the autoregressive coefficient for
the wage markup, is 0.09. Given the point estimate of 0.69, this means that any
given run of the simulator could easily return a mean between 0.5 and 0.9, even
after simulating a Markov chain of length 10 million. In almost all cases, the SMC estimates are about half as noisy, usually substantially less so.
, the autoregressive coefficient for
the wage markup, is 0.09. Given the point estimate of 0.69, this means that any
given run of the simulator could easily return a mean between 0.5 and 0.9, even
after simulating a Markov chain of length 10 million. In almost all cases, the SMC estimates are about half as noisy, usually substantially less so.
Suppose we were able to generate ![]()
![]() draws from the marginal posterior
distribution for a parameter
draws from the marginal posterior
distribution for a parameter ![]() . The variance of the mean of these draws would be given by
. The variance of the mean of these draws would be given by
![]() . Thus, we define
. Thus, we define
![]() , where
, where
![]() is an estimate of the posterior variance of
is an estimate of the posterior variance of ![]() obtained from the output of the SMC algorithm and
obtained from the output of the SMC algorithm and ![]() is the variance of the posterior mean estimate across the 20 runs of each algorithm. The effective sample sizes
is the variance of the posterior mean estimate across the 20 runs of each algorithm. The effective sample sizes ![]() are also reported in Table 2. The
are also reported in Table 2. The ![]() differences across the two algorithms are striking. The SMC algorithm is substantially more efficient, generating effective sample sizes that are one to two orders of magnitudes larger.
differences across the two algorithms are striking. The SMC algorithm is substantially more efficient, generating effective sample sizes that are one to two orders of magnitudes larger.
![]() for the inverse Frisch elasticity of labor supply
for the inverse Frisch elasticity of labor supply ![]() is 1058 for the
SMC algorithm and only 60 for the RWMH. The least efficient numerical approximation is obtained for the posterior mean of the parameters governing the wage (
is 1058 for the
SMC algorithm and only 60 for the RWMH. The least efficient numerical approximation is obtained for the posterior mean of the parameters governing the wage (![]() ,
, ![]() ,
, ![]() ,
, ![]() ) and price (
) and price (![]() ,
, ![]() ,
, ![]() ) stickiness. Under the SMC algorithm,
) stickiness. Under the SMC algorithm, ![]() ranges from 43 to 126, whereas for the
RWMH algorithm, the effective sample size ranges from 1 to 36.
ranges from 43 to 126, whereas for the
RWMH algorithm, the effective sample size ranges from 1 to 36.
We return to Figure 2, which graphically illustrates the precision of the algorithms estimates of the mean, 5th, and 95th percentiles of selected parameters. For the
diffuse prior, the differences across algorithms are more pronounced. First, note that relative to the analysis with the standard prior, the posterior distributions are now more spread out. Second, the precision of the estimates is much lower for the RWMH simulations than for the SMC simulations,
as the black boxes are generally much larger than the red boxes. In fact, the performance of the RWMH algorithm is so poor that for the parameters restricted to the unit intervals, the boxes overlap substantially, meaning that there is sufficient noise in the RWMH algorithm to tangle the, say, 5th
and 95th percentile of the posterior distribution for ![]() . Moreover, the figure confirms the message from Table 2: some of the worst-performing aspects of the RWMH algorithm are associated with the parameters controlling the movements of wages and prices.
. Moreover, the figure confirms the message from Table 2: some of the worst-performing aspects of the RWMH algorithm are associated with the parameters controlling the movements of wages and prices.
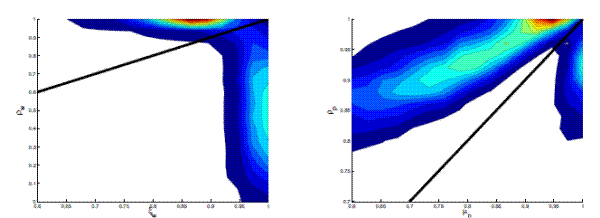
To examine the posterior distribution more closely, we plot joint kernel density estimates of parameters from the wage and price block of the model. The two panels of Figure 3 display joint density estimates of
![]() and
and
![]() .
. ![]() is the autocorrelation parameter in the exogenous
wage-markup shock process, whereas
is the autocorrelation parameter in the exogenous
wage-markup shock process, whereas ![]() is the wage-Calvo parameter that determines the degree of nominal wage rigidity. The parameters
is the wage-Calvo parameter that determines the degree of nominal wage rigidity. The parameters ![]() and
and ![]() are the autoregressive and moving-average coefficients of the exogenous price-markup shock process. The black line
shows the
are the autoregressive and moving-average coefficients of the exogenous price-markup shock process. The black line
shows the ![]() line. It is clear that both panels display multimodal, irregular posterior distributions, exacerbated by hard parameter boundaries.14 For the left panel, it is clear that when the autoregressive coefficient for the exogenous wage-markup parameter,
line. It is clear that both panels display multimodal, irregular posterior distributions, exacerbated by hard parameter boundaries.14 For the left panel, it is clear that when the autoregressive coefficient for the exogenous wage-markup parameter, ![]() , is very close to one, the endogenous wage stickiness of the model, embodied in the wage-Calvo parameter
, is very close to one, the endogenous wage stickiness of the model, embodied in the wage-Calvo parameter ![]() , is less important. On the other
hand, when
, is less important. On the other
hand, when ![]() is close to one, the exogenous persistence of wage movements is much lower. The right panel in Figure 3 shows identification problems related to the coefficients of the ARMA(1,1) price-markup shock process.
is close to one, the exogenous persistence of wage movements is much lower. The right panel in Figure 3 shows identification problems related to the coefficients of the ARMA(1,1) price-markup shock process.
Motivated by the bimodal features of the bivariate posteriors displayed in Figure 3, we graph estimates of posterior probabilities associated with particular regions in the parameter space in Figure 4. According to Figure 3 there exists a mode for
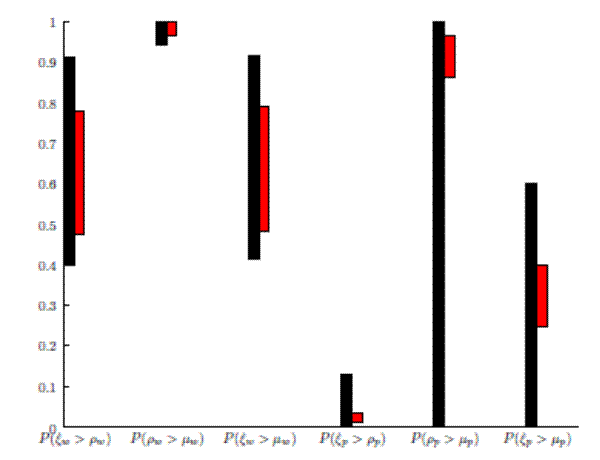
Notes: This Figure shows estimates of various posterior probability statements. The black (RWMH) and red (SMC) boxes are centered at the mean (across the 20 simulations) estimate of each probability statement. The shaded region shows plus and minus two standard deviations around this mean.
which| Parameter | Mode 1 | Mode 2 |
| 0.844 | 0.962 | |
| 0.812 | 0.918 | |
| 0.997 | 0.394 | |
| 0.978 | 0.267 | |
| 0.591 | 0.698 | |
| 0.001 | 0.085 | |
| 0.909 | 0.999 | |
| 0.612 | 0.937 | |
| Log Posterior | -804.14 | -803.51 |
To further explore the multimodal shape of the posterior under the diffuse prior, Table 3 lists the values of the key wage and price parameters at two modes of
the joint posterior density captured by the SMC algorithm.15 With respect to wages, the modes identify two different drivers of fit. At Mode 1, the
values of the wage Calvo parameter, ![]() , and wage indexation parameter,
, and wage indexation parameter, ![]() , are relatively low, while the parameters governing the exogenous wage markup process,
, are relatively low, while the parameters governing the exogenous wage markup process, ![]() and
and ![]() , are high. That is, model dynamics for wages near this mode are driven by the exogenous persistence of the shock. At Mode 2, the relative importance of the parameters is reversed. The persistence of wages is driven by the parameters that
control the strength of the endogenous propagation, echoing the shape in Figure 3. The exogenous wage markup process is much less persistent. We see that the data
support both endogenous and exogenous persistence mechanisms. Thus, a researcher's priors can heavily influence the assessment of the importance of nominal rigidities, echoing a conclusion reached by Del Negro and Schorfheide (2008).
, are high. That is, model dynamics for wages near this mode are driven by the exogenous persistence of the shock. At Mode 2, the relative importance of the parameters is reversed. The persistence of wages is driven by the parameters that
control the strength of the endogenous propagation, echoing the shape in Figure 3. The exogenous wage markup process is much less persistent. We see that the data
support both endogenous and exogenous persistence mechanisms. Thus, a researcher's priors can heavily influence the assessment of the importance of nominal rigidities, echoing a conclusion reached by Del Negro and Schorfheide (2008).
Finally, we return to the marginal data densities, which for the SW model with diffuse prior are reported in the bottom panel of Table 1. The SMC estimate is much more precise, which is unsurprising, given the difficulties of using the modified harmonic mean estimator on a bimodal distribution. The modified harmonic mean estimator actually performs better on the model with diffuse prior than on model with standard prior, mostly because the "height" of the different modes is more similar. Still, the high standard deviation of the estimate indicates severe problems in the algorithm. Finally, as a substantive point, it should be noted that the diffuse prior model has an MDD that is about 30 log points higher than the standard prior SW model. This is a large difference in favor of the diffuse prior model and it highlights the strong tension between the standard prior and the data. This point may apply more generally to DSGE models.
5.3 The Schmitt-Grohe and Uribe News Model
The final application is SGU's "news" model, which has been used to examine the extent to which anticipated shocks (i.e., news) to technology, government spending, wage markups, and preferences explain movements in major macroeconomic time series at business cycle frequencies. The core of the SGU model is a real business cycle model with real rigidities in investment, capital utilization, and wages. While there is not enough space to go through the complete model here, we summarize the key features below. The complete equilibrium conditions for this model are summarized in the Online Appendix.
Important Model Features. We focus on two key features of the SGU model. First, the model has seven exogenous processes in total: stationary and nonstationary technology, stationary and nonstationary investment specific technology, government spending, wage markup, and preference shocks.
Each of the seven processes is driven by three (independent) innovations, one of which is realized contemporaneously, and two of which are realized four and eight quarters ahead. So, the determination of a given exogenous process ![]() looks like:
looks like:
Each innovation
The parameter
The presence of
The model is estimated on seven economic time series: real GDP growth, real consumption growth, real investment growth, real government spending growth, hours, TFP growth and the relative price of investment. The estimation period is 1955:Q1 to 2006:Q4. This model is an interesting application
for the SMC algorithm for several reasons. First, the scale of the model is quite large. There are almost 100 states and 35 estimated parameters. Second, the model contains many parameters for which the priors are quite diffuse, relative to standard priors used in macroeconometrics. In particular,
this is true for the variances of the shocks. Also, the prior for the Jaimovich-Rebelo parameter, ![]() , is uniform across
, is uniform across ![]() . We estimate the SGU model under the prior specified by SGU (tabulated in the Online Appendix) and a modified version of this prior in which we change the distribution of the preference parameter
. We estimate the SGU model under the prior specified by SGU (tabulated in the Online Appendix) and a modified version of this prior in which we change the distribution of the preference parameter ![]() .
.
Tuning of Algorithms. We run the same comparison as in previous sections. For each posterior simulator, we compute 20 runs of the algorithm. For the SMC runs, we use ![]() particles,
particles, ![]() stages,
stages, ![]() ,
, ![]() blocks,
blocks, ![]() , and
, and ![]() . We choose the tuning parameters in a way similar to that for the SW model. We use many more particles because the parameter space is larger and the prior is more diffuse compared to the SW model. Given the high-dimensional parameter vector, we increase
the number of blocks from 3 to 6 to ensure that mutation can still occur. For the RWMH algorithm, we simulate chains of length 10 million, considering only the final 5 million draws. For the proposal density we use a covariance matrix computed from an earlier run, scaled so that the acceptance rate
is roughly 32%. The SMC algorithm takes about 14 hours to run while the RWMH algorithm takes about 4 days. This suggests that a parallelized RWMH algorithm with a speed-up factor of 6.85 would take roughly as long as the SMC algorithm. This is in line with the estimates of Strid (2009), so we
take it that the algorithms are on roughly equal footing in terms of computing power.
. We choose the tuning parameters in a way similar to that for the SW model. We use many more particles because the parameter space is larger and the prior is more diffuse compared to the SW model. Given the high-dimensional parameter vector, we increase
the number of blocks from 3 to 6 to ensure that mutation can still occur. For the RWMH algorithm, we simulate chains of length 10 million, considering only the final 5 million draws. For the proposal density we use a covariance matrix computed from an earlier run, scaled so that the acceptance rate
is roughly 32%. The SMC algorithm takes about 14 hours to run while the RWMH algorithm takes about 4 days. This suggests that a parallelized RWMH algorithm with a speed-up factor of 6.85 would take roughly as long as the SMC algorithm. This is in line with the estimates of Strid (2009), so we
take it that the algorithms are on roughly equal footing in terms of computing power.
| SMC: Parameter | SMC: Mean | SMC:[0.05, 0.95] | SMC: STD(Mean) | SMC: N eff | RWMH: Mean | RWMH:[0.05, 0.95] | RWMH: STD(Mean) | Neff |
|
|
3.14 | [ 0.21, 7.98] | 0.04 | 4190 | 3.08 | [ 0.21, 7.80] | 0.24 | 108 |
| 0.41 | [ 0.03, 0.99] | 0.01 | 1830 | 0.41 | [ 0.03, 0.98] | 0.03 | 108 | |
|
|
5.59 | [ 0.75, 10.59] | 0.09 | 1124 | 5.68 | [ 0.87, 10.54] | 0.30 | 102 |
| 4.13 | [ 3.19, 5.18] | 0.02 | 671 | 4.14 | [ 3.22, 5.19] | 0.05 | 146 | |
|
|
12.27 | [ 9.07, 15.84] | 0.09 | 640 | 12.36 | [ 9.05, 16.12] | 0.09 | 616 |
|
|
1.04 | [ 0.06, 2.79] | 0.04 | 626 | 0.92 | [ 0.06, 2.39] | 0.04 | 625 |
| 0.62 | [ 0.06, 1.08] | 0.01 | 609 | 0.60 | [ 0.06, 1.07] | 0.03 | 111 | |
| 9.32 | [ 7.48, 11.33] | 0.05 | 578 | 9.33 | [ 7.49, 11.40] | 0.09 | 208 | |
|
|
2.43 | [ 0.15, 5.95] | 0.09 | 406 | 2.44 | [ 0.15, 6.04] | 0.04 | 2066 |
|
|
3.82 | [ 0.50, 6.77] | 0.10 | 384 | 3.80 | [ 0.51, 6.78] | 0.22 | 73 |
|
|
2.65 | [ 0.17, 6.22] | 0.11 | 335 | 2.62 | [ 0.17, 6.07] | 0.18 | 126 |
|
|
4.26 | [ 0.28, 5.91] | 0.24 | 49 | 4.33 | [ 0.84, 5.92] | 0.49 | 12 |
|
|
1.36 | [ 0.03, 5.14] | 0.24 | 46 | 1.34 | [ 0.04, 4.83] | 0.49 | 11 |
Results from the SGU Prior. Table 4 displays the posteriors for some of the parameters of the SGU model with the standard prior. It is clear that the
average posterior means from the RWMH and SMC algorithms are roughly the same, with a few exceptions, but that the posteriors generated by the RWMH algorithm are substantially noisier. Mean estimates of parameters associated with news about the wage markup, ![]() and
and ![]() , have standard deviations about twice as large under the RWMH simulator relative to the
SMC simulator. Related, in terms of coverage, the posterior credible interval for the standard deviation of the contemporaneous wage markup shock,
, have standard deviations about twice as large under the RWMH simulator relative to the
SMC simulator. Related, in terms of coverage, the posterior credible interval for the standard deviation of the contemporaneous wage markup shock, ![]() , has a 95% quantile estimate of
2.79 under the SMC algorithm and 2.39 under the RWMH algorithm. Furthermore, the
estimate of the mean of the Jaimovich-Rebelo parameter,
, has a 95% quantile estimate of
2.79 under the SMC algorithm and 2.39 under the RWMH algorithm. Furthermore, the
estimate of the mean of the Jaimovich-Rebelo parameter, ![]() , under the SMC algorithm is outside the 90% credible interval generated by the RWMH algorithm (not listed in Tabl 4). Estimates related to news about the investment specific technology shock,
, under the SMC algorithm is outside the 90% credible interval generated by the RWMH algorithm (not listed in Tabl 4). Estimates related to news about the investment specific technology shock,
![]() and
and
![]() , similarly contain much more Monte Carlo noise under the RWMH. Using the numeric efficiency measure discussed in Section 5.2, there are about 3 times as many independent draws in the SMC samples relative to the RWMH samples, based on the median parameter.
, similarly contain much more Monte Carlo noise under the RWMH. Using the numeric efficiency measure discussed in Section 5.2, there are about 3 times as many independent draws in the SMC samples relative to the RWMH samples, based on the median parameter.
To shed light on the relative performance of the simulators, Figure 5 displays histograms for the
marginal posterior of parameters associated with the wage markup process. For each of the 20 runs we compute separate histograms. Each box is centered at the mean relative histogram height across the 20 runs for the RWMH (black) and SMC (red) algorithms. The shaded rectangles span plus and minus two standard deviations (across the 20 runs) about this mean. We choose evenly-sized bins for the histograms, restricting the span of the bins to a range with non-trivial posterior density. In the upper left panel, the histogram estimates for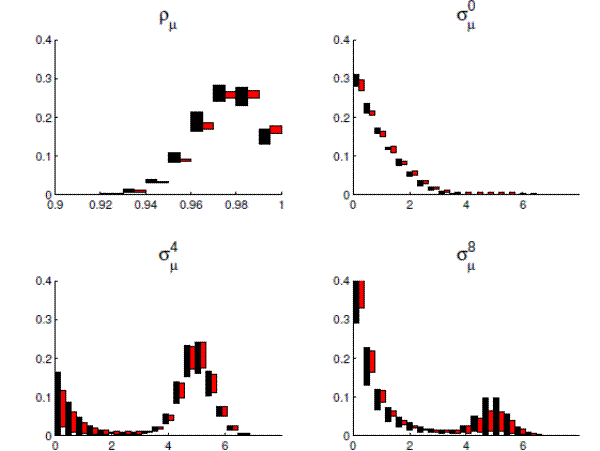
Finally, the bottom two panels of Figure 5 indicate that the RWMH has the most trouble with the multimodalities and irregularities associated with the variances of the news shocks. Looking
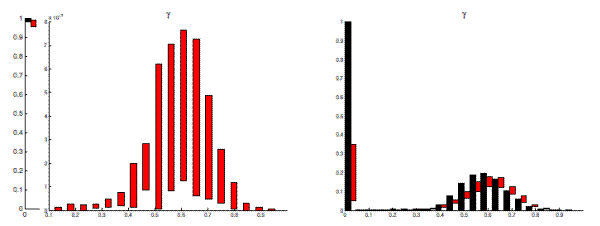
Notes: The boxes show estimates of histograms from each of the simulators. The RWMH algorithm is in red and the SMC is in black. The left panel shows output from the standard prior model and the right panel shows output from the di use prior model. Each box is centered at the mean of the number of elements in each, while the height of the box indicates plus or minus two standard deviations around this mean.
at the size of the boxes, it is clear that these bimodal distributions are more precisely estimated using SMC. For instance,With respect to the Jaimovich-Rebelo parameter, ![]() , the posteriors generated by the RWMH and the SMC algorithm yield small but interesting differences. The left panel of
Figure 6 displays the histograms for the posterior for
, the posteriors generated by the RWMH and the SMC algorithm yield small but interesting differences. The left panel of
Figure 6 displays the histograms for the posterior for ![]() .
The histograms are set up as in Figure 5, with the exception that the left panel has a different scale for the smallest bin. The RWMH algorithm essentially finds a
"pointmass" very close to zero. All of the draws from the RWMH runs are less than 0.03, which we refer to as Mode 1. The SMC algorithm also finds significant posterior probability mass
near zero, but in addition it detects a small mode (Mode 2) around
.
The histograms are set up as in Figure 5, with the exception that the left panel has a different scale for the smallest bin. The RWMH algorithm essentially finds a
"pointmass" very close to zero. All of the draws from the RWMH runs are less than 0.03, which we refer to as Mode 1. The SMC algorithm also finds significant posterior probability mass
near zero, but in addition it detects a small mode (Mode 2) around ![]() , comprising about 3% of the total posterior. This can be seen again by looking at the red boxes to the
right of 0.1, vs. the non-existent black boxes. Keep in mind though, that the scale for Mode 2 is magnified relative to Mode 1.
, comprising about 3% of the total posterior. This can be seen again by looking at the red boxes to the
right of 0.1, vs. the non-existent black boxes. Keep in mind though, that the scale for Mode 2 is magnified relative to Mode 1.
The two modes have very different economic implications. Near Mode 2 the wealth effect associated with an increase in income is nonzero. This changes the dynamics of the news model: positive news about the future tend to decrease labor supplied today, because consumers anticipate higher
income in the future. Indeed, a parameter value of
![]() implies that the importance of anticipated shocks for hours is substantially diminished. To compensate for the reduced importance of anticipated shocks, values of
implies that the importance of anticipated shocks for hours is substantially diminished. To compensate for the reduced importance of anticipated shocks, values of
![]() are associated with high standard deviations of the unanticipated wage-markup shock. Overall, a variance decomposition implies that conditional on
are associated with high standard deviations of the unanticipated wage-markup shock. Overall, a variance decomposition implies that conditional on
![]() , unanticipated movements in the wage markup account for about 50% of the movement in hours, compared with just 10% of the movement when
, unanticipated movements in the wage markup account for about 50% of the movement in hours, compared with just 10% of the movement when
![]() . Thus, for parameters near Mode 2, movements in hours are not principally driven by news.
. Thus, for parameters near Mode 2, movements in hours are not principally driven by news.
Results from a Modified Prior. To highlight this potential pitfall more clearly, we re-estimate the news model under a different prior for ![]() , namely,
, namely,
![]() Relative to the uniform prior, this prior places more mass on the region near 1. Its probability density function is a 45-degree line. A possible justification
for this prior is that it places more weight on the "standard" utility functions used in the macroeconomics literature. Mechanically, this prior causes Mode 2 in the original SGU model to become more important. Indeed, now most of the mass resides in this region, although the peak at
Relative to the uniform prior, this prior places more mass on the region near 1. Its probability density function is a 45-degree line. A possible justification
for this prior is that it places more weight on the "standard" utility functions used in the macroeconomics literature. Mechanically, this prior causes Mode 2 in the original SGU model to become more important. Indeed, now most of the mass resides in this region, although the peak at
![]() is still important. The heights of the two modes in the posterior distribution of
is still important. The heights of the two modes in the posterior distribution of ![]() is approximately equal under the modified prior. The right panel of Figure 6displays the histogram estimates for
is approximately equal under the modified prior. The right panel of Figure 6displays the histogram estimates for ![]() under the new prior for 20 runs each of the RWMH (black) and the SMC (red) algorithms. One can see that the estimates for
under the new prior for 20 runs each of the RWMH (black) and the SMC (red) algorithms. One can see that the estimates for ![]() are now extremely noisy, place anywhere from 0 to 1 probability mass in the region
are now extremely noisy, place anywhere from 0 to 1 probability mass in the region ![]() for the RWMH, indicating that some runs of the RWMH did not mix on both
modes. The reason for this is that the peak around
for the RWMH, indicating that some runs of the RWMH did not mix on both
modes. The reason for this is that the peak around
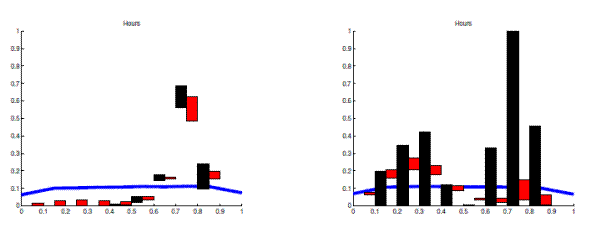
Notes: The boxes show estimates of histograms for the share of long-run variance in hours attributable to news shocks from each of the simulators. The RWMH algorithm is in red and the SMC is in black. The prior share is shown with the blue line. The left panel shows output from the standard prior model and the right panel shows output from the modified prior model. Each box is centered at the mean of the number of elements in each, while the height of the box indicates plus or minus two standard deviations around this mean.
To see how this translates into problems for substantive economic inference, Figure 7 plots the histograms for the share of the long-run variance in hours accounted for
by anticipated shocks under both priors along with the prior shares. Under the standard prior, both simulators generate roughly the same posterior variance shares, although the SMC has a slightly longer left tail due to the small second mode, and to be sure, this tail is relatively imprecisely
estimated (as it is small). Once the prior for ![]() is changed to a
is changed to a
![]() distribution, the problems associated with the RWMH are exacerbated and inference is substantially changed. As with the posterior for
distribution, the problems associated with the RWMH are exacerbated and inference is substantially changed. As with the posterior for ![]() , the RWMH places anywhere from 0 to 1 probability mass on the anticipated shocks accounting for 80% of the long-run movements in hours. The bimodal shape of the posterior distribution distribution of the news shock
share under the modified prior is much more precisely estimated by the SMC algorithm and the economic inference is not overwhelmed by Monte Carlo noise. Relative to the standard prior, news shocks are much less important in determining the behavior of hours.
, the RWMH places anywhere from 0 to 1 probability mass on the anticipated shocks accounting for 80% of the long-run movements in hours. The bimodal shape of the posterior distribution distribution of the news shock
share under the modified prior is much more precisely estimated by the SMC algorithm and the economic inference is not overwhelmed by Monte Carlo noise. Relative to the standard prior, news shocks are much less important in determining the behavior of hours.
| Algorithm (Method) | MEAN(Log MDD) | STD(Log MDD) |
| SGU Prior: SMC (Particle Estimate) | -1802.15 | 0.23 |
| SGU Prior: RWMH (Modified Harmonic Mean) | -1800.77 | 0.35 |
| Modified Prior: SMC (Particle Estimate) | -1805.00 | 0.11 |
| Modified Prior: RWMH (Modified Harmonic Mean) | -1836.42 | 7.72 |
Finally, we report log marginal data density estimates in Table 5. As in the case of the Smets-Wouters model, the modified harmonic mean estimate computed from the
output of the RWMH algorithm is more noisy, in particular under the modified prior. It turns out that the data slightly favor the model specification with the original SGU prior distribution, but further modifications, e.g. larger prior variances, may easily overturn this ranking. While the
analysis under the modified prior was designed to highlight the merit of the SMC sampler, it makes an empirical point as well: Conclusions about the importance of news as a drivers of the business cycle are very sensitive to prior choices. By pushing the prior for ![]() towards more standard values in the literature, we were able to reduce the effect of news on hours substantially. This result signals cautious interpretation of DSGE model-based estimates of the importance (or lack
thereof) of news on the business cycle.
towards more standard values in the literature, we were able to reduce the effect of news on hours substantially. This result signals cautious interpretation of DSGE model-based estimates of the importance (or lack
thereof) of news on the business cycle.
6 Conclusion
This paper has presented an alternative simulation technique for estimating Bayesian DSGE models. We showed that, when properly tailored to DSGE models, a sequential Monte Carlo technique can be more effective than the random-walk Metropolis Hastings algorithm. The RWMH is poorly suited to dealing with complex and large posteriors, while SMC algorithms, by slowly building a particle approximation of the posterior, can overcome the problems inherent in multimodality. This is important for DSGE models, where the parameters enter the likelihood in a highly nonlinear fashion and identification problems may be present. We have seen in both the SW model and the SGU model that when priors are not very informative, the posterior can possess multimodalities. It is difficult to correctly characterize the posterior with the RWMH in this case. Moreover, the SMC algorithm has an embarrassingly parallelizable structure. Within each tempering iteration, likelihoods can be evaluated simultaneously. In most programming languages, this kind of parallelism can be employed easily, for example, MATLAB's parfor command. Finally, we have shown that the sequential Monte Carlo methods can be used for very large DSGE models. Indeed, it is on large complex distributions that returns to using an SMC algorithm over an MCMC algorithm are highest.
Bibliography
Amdahl, G. (1967): \Validity of the Single Processor Approach to Achieving Large-Scale Computing Capabilities,''AFIPS Conference Proceedings, 30, 483-485.
Cappe, O., E. Moulines, and T. Ryden (2005): Inference in Hidden Markov Models. Springer Verlag.
Chib, S.,and S. Ramamurthy (2010): ''Tailored Randomized Block MCMC Methods with Application to DSGE Models,'' Journal of Econometrics, 155(1), 19-38.
Chopin, N. (2002): ''A Sequential Particle Filter for Static Models,'' Biometrika, 89(3), 539-551.
Chopin, N. (2004): ''Central Limit Theorem for Sequential Monte Carlo Methods and its Application to Bayesian Inference,''Annals of Statistics, 32(6), 2385-2411.
Creal, D. (2007): ''Sequential Monte Carlo Samplers for Bayesian DSGE Models,'' Unpublished Manuscript, Vrije Universitiet.
Creal, D. (2012): ''A Survey of Sequential Monte Carlo Methods for Economics and Finance,'' Econometric Reviews, 31(3), 245-296.
Creal, D., S. J. Koopman, and N. Shephard (2009): \Testing the Assumptions Behind Importance Sampling,''Journal of Econometrics, 149, 2-11.
Curdia, V.,and R. Reis (2010): ''Correlated Disturbances and U.S. Business Cycles,'' Manuscript, Columbia University and FRB New York.
DeJong, D. N., B. F. Ingram, and C. H. Whiteman (2000): ''A Bayesian Approach to Dynamic Macroeconomics,''Journal of Econometrics, 98(2), 203- 223.
Del Moral, P., A. Doucet, and A. Jasra (2006): ''Sequential Monte Carlo Samplers,'' Journal of the Royal Statistical Society, Series B, 68(Part 3), 411-436.
Del Negro, M., and F. Schorfheide (2008): ''Forming Priors for DSGE Models (and How it Affects the Assessment of Nominal Rigidities),'' Journal of Monetary Economics, 55(7), 1191-1208.
Del Negro, M., and F. Schorfheide (2013): \DSGE Model-Based Forecasting,'' in Handbook of Economic Forecasting, ed. by G. Elliott, and A. Timmermann, vol. 2, forthcoming. North Holland, Amsterdam.
Durham, G., and J. Geweke (2012): ''Adaptive Sequential Posterior Simulators for Massively Parallel Computing Environments,'' Unpublished Manuscript.
Geweke, J. (1989): ''Bayesian Inference in Econometric Models Using Monte Carlo Integration,'' Econometrica, 57(6), 1317-1399.
Geweke, J (1999): ''Using Simulation Methods for Bayesian Econometric Models: Inference, Development, and Communication,'' Econometric Reviews, 18(1), 1-126.
Greenwood, J., Z. Hercowitz, and G. Huffman (1988): ''Investment, Capacity Utilization, and the Real Business Cycle,''American Economic Review, 78(3), 402-417.
Herbst, E. (2011): ''Gradient and Hessian-based MCMC for DSGE Models,'' Unpublished Manuscript, University of Pennsylvania.
Herbst, E. (2012): ''Using the ''Chandrasekhar Recursions'' for Likelihood Evaluation of DSGE Models,'' FEDS Paper, (2012-11).
Jaimovich, N., and S. Rebelo (2009): ''Can News about the Future Drive the Business Cycle?,'' American Economic Review, 9(4), 1097-1118.
King, R. G., C. I. Plosser, and S. Rebelo (1988): ''Production, Growth, and Business Cycles: I The Basic Neoclassical Model,''Journal of Monetary Economics , 21(2-3), 195-232.
Kohn, R., P. Giordani, and I. Strid (2010): ''Adaptive Hybrid Metropolis-Hastings Samplers for DSGE Models,'' Working Paper.
Liu, J. S. (2008): Monte Carlo Strategies in Scientific Computing. Springer Verlag.
Muller, U. (2011):''Measuring Prior Sensitivity and Prior Informativeness in Large Bayesian Models,'' Manuscript, Princeton University.
Neal, R. (2003): ''Slice Sampling (with discussion),'' Annals of Statistics , 31, 705-767.
Otrok, C. (2001): ''On Measuring the Welfare Costs of Business Cycles,'' Journal of Monetary Economics, 47(1), 61-92.
Pollard, D. (2002): A User's Guide to Measure Theoretic Probability. Cambridge University Press.
Rabanal, P., and J. F. Rubio-Ramirez (2005): \Comparing New Keynesian Models of the Business Cycle: A Bayesian Approach,'' Journal of Monetary Economics, 52(6), 1151-1166.
Rosenthal, J. S. (2000): ''Parallel Computing and Monte Carlo Algorithms,'' Far East Journal of Theoretical Statistics, 4, 207-236.
Schmitt-Grohe, S., and M. Uribe (2012): ''What's News in Business Cycles?,'' Econometrica, forthcoming.
Schorfheide, F. (2000): ''Loss Function-based Evaluation of DSGE Models,'' Journal of Applied Econometrics, 15, 645-670.
Schorfheide, F. (2010): ''Estimation and Evaluation of DSGE Models: Progress and Challenges,'' NBER Working Paper.
Smets, F., and R. Wouters (2007): ''Shocks and Frictions in US Business Cycles: A Bayesian DSGE Approach,'' American Economic Review, 97, 586-608.
Strid, I. (2009): ''Effocoemt Parallelisation of Metropolis-Hastings Algorithms Using a Prefetching Approach,'' Computational Statistics and Data Analysis, in press.