Signal Extraction for Nonstationary Multivariate Time Series with Illustrations for Trend Inflation
Keywords: Co-integration, common trends, filters, multivariate models, stochastic trends, unobserved components.
Abstract:
JEL Classification: C32
Disclaimer
This report is released to inform interested parties of research and to encourage discussion. The views expressed on statistical issues are those of the author and not necessarily those of the U.S. Census Bureau or the Federal Reserve Board.
1 Introduction
In many scientific fields, research and analysis make widespread use of a signal extraction paradigm. Often, interest centers on underlying dynamics (such as trend, non-seasonal, and cyclical parts or, more generally, systematic movements) of time series also subject to other, less regular components such as temporary fluctuations. In such cases, the resulting strategy involves the estimation of signals in the presence of noise. For instance, economists and policy-makers routinely want to assess major price trends, cycles in industrial and commercial activity, and other pivotal indicators of economic performance. Typically, the measurement of such signals combines judgmental elements with precise mathematical approaches.
Here, we concentrate on the latter aspect, with the goal of developing the formal apparatus for detecting signals in a comprehensive econometric framework, motivated by two basic considerations. First, the signal extraction problems relevant to experience usually involve more than one variable; at central banks, for instance, staff use a range of available series to monitor prevailing inflationary conditions. Second, economic data often involve nonstationary movements, with (possibly close) statistical relationships among the stochastic trends for a set of indicators.
In this paper we generalize the existing theory and methodology of signal extraction to multivariate nonstationary time series. In particular, we set out analytical descriptions of optimal estimator structures that emerge from a wide range of signal and noise dynamics, both for asymptotic and for finite sample cases. Our results give a firm theoretical basis for the expansion of the Wiener-Kolmogorov (WK) formula to the nonstationary multivariate framework and provide a simple and direct method (distinct from the state space approach) for calculating signal estimates and related quantities, and for studying endpoint effects explicitly. In presenting these formulas, we also treat the case of co-integrated systems, which, as with other econometric problems, has special implications for the characteristics of the signal estimators. Previously, many applications of signal extraction have been undertaken without such a rigorous foundation. Such a basis unveils properties of signal estimators, and hence allows for a host of developments, such as the design of new architectures from the collective dynamics for signal and noise vector processes and the analysis of signal location effects in finite series.
The previous literature in this area, which handles only single series or stationary vector series, has a long history. For a doubly infinite data process, Wiener (1949) and Whittle (1963) made substantial early contributions; the corresponding WK formula, which gives the asymptotic form (for historical, or two-sided smoothing) of the relationship between optimal signal estimation and the component properties, has become a theoretical benchmark in time series econometrics. The original WK filters assumed stationary signal and noise vector processes, whose properties entered directly into the expressions through their autocovariance generating functions (ACGF). With awareness about the importance of nonstationarity in time series analysis growing through the early 1980s, Bell (1984) proved the optimality of an analogous bi-infinite filter for nonstationary data. However, despite the widespread knowledge of correlated movements among related variables in macroeconomics and in other disciplines, which has motivated an enormous amount of research on multivariate time series models over the last several decades, the relevant theory has not yet been provided for multiple nonstationary series.
Past theoretical work on signal extraction for finite samples has concentrated on single series (see Bell (2004) and McElroy (2008) and the references therein). Most economic applications have relied on standard Kalman filtering and smoothing algorithms, for instance the trend-cycle analyses in Harvey and Trimbur (2003), Azevedo et al. (2006), and Basistha and Startz (2008). The implied weights on the input series may be computed in each case with an augmentation of the basic algorithms, as in Koopman and Harvey (2003); yet this method omits closed-form expressions or explicit information about the functional form of the filters. Bell (1984) introduced some exact results; subsequently, the compact formulas in McElroy (2008) provided a considerable simplification, amenable to simple implementation (and possibly other uses, such as analytical investigation of end-point effects). However, to our knowledge, the finite sample theory has not yet been presented for multivariate signal-noise processes, whether stationary or nonstationary.
As a primary goal, this paper presents new results on signal estimation in doubly-infinite time series for multivariate nonstationary models. These expressions capture the basic action - independent of signal location and sample size - of the estimators, leading to compact expressions in the time and frequency domains that give complete descriptions of the operators' effects. Our generalization of the WK formula provides a firm mathematical foundation for the construction of jointly optimal estimators for multiple series, and reveals explicitly how signal extraction architectures, having the form of matrix filter expressions, emerge from the collective dynamics of signal and noise vectors.
We also introduce signal extraction results for finite samples, generalizing the analysis in McElroy (2008) to multivariate systems including nonstationary1 series. The formulas give a very general mapping from stochastic signal-noise models to optimal estimators at each point in finite sample vector series. This reveals the explicit weighting patterns on the observation vectors for estimation close to the end of the series, which is a crucial problem for generating signals central to current analysis and economic decision-making. Having such an optimal accounting for the finite series length seems especially helpful for multiple series; compared to the univariate setup, in addition to the position effect, we now have collections, or matrices, of time-dependent and asymmetric filters with complex inter-relationships for each time period. More generally, our results incorporate the complete functional dependence of the filter set on parameters, sample size, and estimate location, so they include the interaction of signal-noise dynamics with distance to end-point and series length in the formation of the optimal weight vectors. In contrast to the state space approach, our matrix expressions enable straightforward and direct computation of multivariate signals, as well as providing additional information, such as the estimation error covariance across individual signals and across different times. The matrix expressions are also more widely applicable than the state space smoother, because some processes of interest (e.g., long-range dependent processes) cannot be embedded in a state space framework.
Signals of interest typically have an interpretation; for instance, stochastic trends capture permanent or long-run movements and underpin the nonstationarity found in most economic time series. The trend components usually dominate the historical evolution of series and prove crucial for understanding and explaining the major or lasting transitions over an existing sample. Toward the end-points, they may account for an important part of recent movements, that are likely to propagate into the new observations that will become available for the present and future periods. Hence, accurate estimation of stochastic trends often represents a signal extraction problem of direct interest, giving a pivotal input for assessing patterns in past behavior and for current analysis and near-term projection.
We apply our theoretical developments on two stochastic trend models widely used in the literature. Simple dynamic representations are used to demonstrate the combination of nonstationary and stationary parts, that occurs in many economic time series. For richer models, in separating trend from noise, the key aspects illustrated by our examples continue to drive the best signal estimators: the form of nonstationary component, its strength relative to the noise for each series, and the interactions among series for each component. Of course, the treatment of stochastic trends, where present, also crucially affects other areas such as measurement of cyclical or seasonal parts, given the reciprocity of the estimation problem for the various components in a set of series.
We also address the case of common (or co-integrated) trends, and explore its implications for signal estimation. Starting with early work such as Engle and Granger (1987), Stock and Watson (1988), and Johansen (1988), the importance of such co-movements for econometric methodology has been long established, based on their impact on statistical theory and estimator properties, along with the evidence for their frequent occurrence found by researchers. While related to VAR-based formulations, such as Engle and Granger (1987) and Johansen (1988), the common trends form, as presented in Stock and Watson (1988), allows us to directly handle tightly linked long-term signals, and is also useful beyond this context. For instance, this formulation makes available a different class of tests for the integration order of processes, as in Nyblom and Harvey (2000). Here, we allow for the presence of co-integration in the formulation of our general theorems.
We present an application of the above models to the measurement of trend inflation with data on both core and total inflation. Using these time series models as the basis of the signal estimation ensures consistency with the dynamic properties and cross-relationships of the bivariate inflation. Our extensions to signal extraction theory allow us to derive the precise estimators of the trend in total inflation. These results (which differ from trend measurement with a simple reliance on core alone) quantify the degree of emphasis on core and the corresponding down-weighting of total, expressed in either the time or frequency domains.
The rest of the paper is arranged as follows. Section 2 develops the generalized WK formula for a set of nonstationary time series, expressing the optimal multivariate filters in both the frequency and time domains. Exact signal extraction results for a finite-length dataset are derived in Section 3. Then Section 4 reviews some major models for multivariate stochastic trends, and the methodology is illustrated by the statistical measurement of trend inflation using both core and total inflation data. Section 5 provides our conclusions, and mathematical proofs are in the Appendix.
2 Multivariate signal extraction from a bi-infinite sample
This section gives a highly general solution to the signal extraction problem for multiple nonstationary series and generalizes the WK formula to this case. The aim of signal extraction is to elicit components of interest - the signals - from series that also contain other components. Signal-noise decompositions have the form of unobserved component (UC) processes, where the signal processes (which may take the form of a combination of two or more distinct latent processes) typically have an interpretation, such as a stochastic trend, that suggest some dynamic formulation. The noise combines all the remaining components in the series; then, to achieve the goal of extracting the target signals, we may use an appropriate filter to remove the unwanted effects of the noise. The WK formula produces the optimal estimator of the signals in terms of the dynamics of the UC processes, so it shows how component structure maps into filter design. In this way, the filters that emerge from the formula have the major advantages of coherency with each other and - by setting parameters in accordance with a fitted model - of consistency with the set of input series.
In formulating the theory behind multivariate signal extraction, we first treat the benchmark case of a hypothetical doubly infinite process. In the next section we examine the estimation problem based upon a finite sample. The bi-infinite case is useful for studying the fundamental and long-term impact of filters, as it abstracts from near-end-of-sample effects and allows one to derive mathematical expressions in terms of the specifications of components and parameter values that capture the essence of the signal extraction mechanism. This theoretical framework generally proves most useful for analysis in the frequency domain, for which signal estimators typically give rise to gain functions of a compact form, making possible the transparent and straightforward comparison of optimal filters across different models. The doubly infinite assumption represents a natural limiting case, with estimators based on the maximum information set, and in practice, for long enough samples, it applies approximately to most of the time points in a wide neighborhood around the mid-point.
We first set out our notation and some basic concepts; also see Brockwell and Davis (1991). Consider a vector-valued, possibly nonstationary, time series denoted
![]() , with each
, with each
![]() of dimension
of dimension ![]() A multivariate filter for a set of
A multivariate filter for a set of ![]() series has the expression
series has the expression
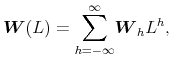
where
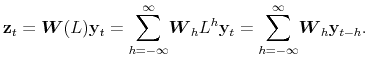
Therefore, the weight matrix
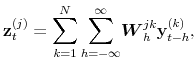 |
where
The filter output for each ![]() equals a sum of
equals a sum of ![]() terms, each given by a weighting
kernel applied to an element series. For
terms, each given by a weighting
kernel applied to an element series. For ![]() , we will call the profile of weights an auto-filter, while for distinct indices they will be called a cross-filter, i.e., the weights for the
signal are applied to a different series. We now have
, we will call the profile of weights an auto-filter, while for distinct indices they will be called a cross-filter, i.e., the weights for the
signal are applied to a different series. We now have ![]() input series for each output series, so there are
input series for each output series, so there are ![]() filters to consider.
filters to consider.
The spectral representation for a stationary multivariate time series (see Chapter 11.6 of Brockwell and Davis (1991)) involves a vector-valued orthogonal increments process
![]() for frequencies
for frequencies
![]() defined as
defined as
![]() . When this is well-defined, the spectral density matrix
. When this is well-defined, the spectral density matrix
![]() is defined via
is defined via
![]() divided by
divided by ![]() , and
describes the second moment variation in terms of power at different frequencies. The diagonal entries of
, and
describes the second moment variation in terms of power at different frequencies. The diagonal entries of
![]() are the spectral densities of the component processes of
are the spectral densities of the component processes of
![]() , whereas the off-diagonal entries are cross-spectral densities that summarize the relationships across series for the range of frequency parts. The output of the filter
, whereas the off-diagonal entries are cross-spectral densities that summarize the relationships across series for the range of frequency parts. The output of the filter
![]() is expressed in the frequency domain as
is expressed in the frequency domain as
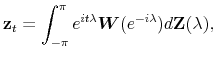
with the quantity
For many filters of interest, including those we study in Section 4 below,
![]() for all
for all ![]() , which implies the frf is
real-valued. In this case there is no phase shift (see Brockwell and Davis (1991)) and the frf is identical with the Gain function, denoted
, which implies the frf is
real-valued. In this case there is no phase shift (see Brockwell and Davis (1991)) and the frf is identical with the Gain function, denoted
![]() , i.e.,
, i.e.,
![]() . We focus on this case in what follows; if we examine the action for the
. We focus on this case in what follows; if we examine the action for the ![]() th component output process, we have
th component output process, we have
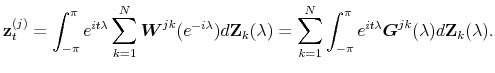 |
So the gain is a
As noted above, the spectral density
![]() gives a breakdown of the second order structure of a vector time series. An equivalent tool is the multivariate autocovariance generating function (ACGF), which for any mean
zero stationary series
gives a breakdown of the second order structure of a vector time series. An equivalent tool is the multivariate autocovariance generating function (ACGF), which for any mean
zero stationary series
![]() is written as
is written as
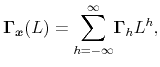 |
where
So far we have reviewed multivariate filters and properties of stationary vector time series. Now, the basic aim of signal extraction is to estimate a target signal
![]() , in a series
, in a series
![]() of interest, or equivalently, to remove the remainder
of interest, or equivalently, to remove the remainder
![]() , called the noise. A precise formulation is given by
, called the noise. A precise formulation is given by
(for all
The problem of multivariate signal extraction is to compute, for each ![]() and at each time
and at each time ![]() ,
,
![]() , the estimate that minimizes the Mean Squared Error (MSE) criterion. Interest centers on linear optimal estimators following Whittle
(1963), as usually undertaken in the literature. The linear solution is, strictly speaking, only appropriate for Gaussian data. That is, the mean of the signal, conditional on the observations, is always given by a linear filter only under normality. For non-Gaussian data, the linear estimates
constructed here do not yield the conditional expectation in all cases2. However, for any type of white noise distribution, our linear estimators are still
minimum MSE among all linear estimators.
, the estimate that minimizes the Mean Squared Error (MSE) criterion. Interest centers on linear optimal estimators following Whittle
(1963), as usually undertaken in the literature. The linear solution is, strictly speaking, only appropriate for Gaussian data. That is, the mean of the signal, conditional on the observations, is always given by a linear filter only under normality. For non-Gaussian data, the linear estimates
constructed here do not yield the conditional expectation in all cases2. However, for any type of white noise distribution, our linear estimators are still
minimum MSE among all linear estimators.
In the case that both the signal and noise processes are stationary, the optimal filter for extracting the signal vector is
where WK stands for the Wiener-Kolmogorov filter (see Wiener (1949); the formula under stationarity is also discussed more recently in Gómez (2006)). The filter for extracting the noise is
Now (5) gives the time-domain characterization, which when expressed in the form (1) shows the matrix weights applied to the series to extract the signal vector in a bi-infinite sample. To convert to the frequency domain, substitute
![]() for
for ![]() , which then produces the WK frf:
, which then produces the WK frf:
where the quantities
Below, we extend this result to the nonstationary case, both under very general conditions on the component structure and under the similar specification form that usually holds for multivariate models used in research and applications, generalizing the classic results of Bell (1984). The first
formulation involves detailed results allowing for a flexible form where the component design may differ across series. This would include, for instance, a situation where series have stochastic trends with different orders of integration. The second version refers to the uniform nonstationary
operators form, often used in time series analysis, where the component orders of integration are the same across variables. Within this form, there are two possible portrayals: first, in terms of ACGFs of "over-differenced" signal and noise processes,
![]() and
and
![]() defined below, in which case the stationarity of the processes immediately guarantees that the filter and its frf are well-defined; or second, explicitly in terms of
signal and noise ACGFs (called pseudo-ACGFs when the component is nonstationary), which is directly analogous to (5) in terms of stationary ACGFs, in which case existence and convergence of the filter and its frf can be verified by taking appropriate limits.
defined below, in which case the stationarity of the processes immediately guarantees that the filter and its frf are well-defined; or second, explicitly in terms of
signal and noise ACGFs (called pseudo-ACGFs when the component is nonstationary), which is directly analogous to (5) in terms of stationary ACGFs, in which case existence and convergence of the filter and its frf can be verified by taking appropriate limits.
For the multivariate signal and noise processes, we consider all processes that are difference-stationary: there is a "minimal" differencing operator (a polynomial in the lag operator that has all roots on the unit circle), and there is no way to factor the polynomial so that the remaining factors form an operator that by itself renders the process stationary. This includes openly formulated VARIMA specifications (see the discussion in Lütkepohl (2006) on integrated processes), or structural forms that involve intuitive restrictions (that help in model parsimony and interpretability).
We will use the term "core," to refer to the mean zero, covariance stationary process resulting from differencing. Note that the noise process may be nonstationary as well, but the differencing polynomials must be different from those of the signal process. This involves no loss of generality in practice; it is a simple requirement for keeping signal and noise well-defined. Components may also have co-integration or co-linearity, expressed as having a spectral density matrix for the core process that is singular at some (finite set of) frequencies.
Consider the ![]() th observed process,
th observed process,
![]() . Since it is a difference-stationary process (e.g., VARIMA), by definition there exists an order
. Since it is a difference-stationary process (e.g., VARIMA), by definition there exists an order ![]() polynomial
polynomial
![]() in the lag operator
in the lag operator ![]() such that
such that
![]() is covariance stationary. Similarly, we suppose there are signal and noise differencing polynomials
is covariance stationary. Similarly, we suppose there are signal and noise differencing polynomials
![]() and
and
![]() that render each of them stationary, so that
that render each of them stationary, so that
![]() and
and
![]() . As a special and leading case, it may occur that the signal and noise differencing operators do not depend
on
. As a special and leading case, it may occur that the signal and noise differencing operators do not depend
on ![]() , so that they are the same for each series (though they still differ for signal versus noise); we refer to this situation as "uniform differencing operators."
, so that they are the same for each series (though they still differ for signal versus noise); we refer to this situation as "uniform differencing operators."
Let
![]() ,
,
![]() , and
, and
![]() denote the cross-spectral density functions for the
denote the cross-spectral density functions for the ![]() th and
th and ![]() th processes for the signal, noise, and observed processes, respectively. These functions are the components of spectral matrices (which are functions of the frequency
th processes for the signal, noise, and observed processes, respectively. These functions are the components of spectral matrices (which are functions of the frequency
![]() ) denoted
) denoted
![]() ,
,
![]() , and
, and
![]() . We suppose that
. We suppose that
![]() is invertible almost everywhere, i.e., the set
is invertible almost everywhere, i.e., the set ![]() of frequencies where
of frequencies where
![]() is noninvertible has Lebesgue measure zero. Note that if the data process is co-integrated (in the sense of Engle and Granger (1987)), then
is noninvertible has Lebesgue measure zero. Note that if the data process is co-integrated (in the sense of Engle and Granger (1987)), then
![]() is singular, but
is singular, but
![]() is invertible for
is invertible for
![]() . However (as shown below), if the innovations for
. However (as shown below), if the innovations for
![]() are co-linear (i.e., the covariance of the white noise process has determinant zero) then
are co-linear (i.e., the covariance of the white noise process has determinant zero) then
![]() is singular for all values of
is singular for all values of ![]() , and
our results don't apply - but neither is conventional model estimation possible. See the further discussion following Theorems 1 and 2. It is convenient to define the so-called "over-differenced" processes given by
, and
our results don't apply - but neither is conventional model estimation possible. See the further discussion following Theorems 1 and 2. It is convenient to define the so-called "over-differenced" processes given by
These occur when the full-differencing operator
Next, we assume that the vector processes
![]() and
and
![]() are uncorrelated with one another. This is reasonable when signal and noise are driven by unrelated processes; for instance, the trend may be linked to long-run factors
(like the setting of contracts), while the short-run run noise stems from temporary forces. The assumption of zero correlation also seems a natural choice when a correlation restriction is required for identification.
are uncorrelated with one another. This is reasonable when signal and noise are driven by unrelated processes; for instance, the trend may be linked to long-run factors
(like the setting of contracts), while the short-run run noise stems from temporary forces. The assumption of zero correlation also seems a natural choice when a correlation restriction is required for identification.
Note that each nonstationary process
![]() can be generated from
can be generated from ![]() stochastic initial values
stochastic initial values
![]() together with the disturbance process
together with the disturbance process
![]() , for each
, for each ![]() , in the manner elucidated for the
univariate case in Bell (1984). The information contained in
, in the manner elucidated for the
univariate case in Bell (1984). The information contained in
![]() is equivalent to that in
is equivalent to that in
![]() for the purposes of linear projection, since the former is expressible as a linear transformation of the latter, for each
for the purposes of linear projection, since the former is expressible as a linear transformation of the latter, for each ![]() . In model fitting and forecasting applications, a working assumption on vector time series is that these initial values
. In model fitting and forecasting applications, a working assumption on vector time series is that these initial values
![]() are uncorrelated with the disturbance process
are uncorrelated with the disturbance process
![]() ; we will assume a stronger condition that actually implies this assumption.
; we will assume a stronger condition that actually implies this assumption.
Assumption
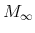 .
.
Suppose that, for each
![]() , the initial values
, the initial values
![]() are uncorrelated with the vector signal and noise core processes
are uncorrelated with the vector signal and noise core processes
![]() and
and
![]() .
.
This assumption generalizes the univariate Assumption A of Bell (1984) to a multivariate framework - each set of initial values
![]() are orthogonal not only to the signal and noise core processes for the
are orthogonal not only to the signal and noise core processes for the ![]() th series, but for all
th series, but for all ![]() series. Set
series. Set
![]() and
and
![]() , and utilize the following notation, that for any matrix
, and utilize the following notation, that for any matrix ![]() the matrix consisting of only the diagonal entries is written
the matrix consisting of only the diagonal entries is written
![]() . Then for nonstationary (and possibly co-integrated) multivariate time series, the optimal estimator of the signal, conditional on the observations
. Then for nonstationary (and possibly co-integrated) multivariate time series, the optimal estimator of the signal, conditional on the observations
![]() , for each
, for each ![]() and at each time
and at each time ![]() , is given by a multivariate filter
, is given by a multivariate filter
![]() described below.
described below.
Theorem 1 Assume that
![]() is invertible for each
is invertible for each ![]() in a subset
in a subset
![]() of full Lebesgue measure. Also suppose that the vector processes
of full Lebesgue measure. Also suppose that the vector processes
![]() and
and
![]() are uncorrelated with one another, and that Assumption
are uncorrelated with one another, and that Assumption
![]() holds. Denote the cross-spectra between
holds. Denote the cross-spectra between
![]() and
and
![]() via
via
![]() , which has
, which has ![]() th entry
th entry
![]() . Similarly, denote the cross-spectra between
. Similarly, denote the cross-spectra between
![]() and
and
![]() via
via
![]() . Also, let
. Also, let
![]() denote the diagonal matrix with entries
denote the diagonal matrix with entries
![]() . Consider the filter
. Consider the filter
![]() defined as follows: it has frf defined for all
defined as follows: it has frf defined for all
![]() via the formula
via the formula
Moreover, we suppose that this formula can be continuously extended to
When the differencing operators are uniform, a compact matrix formula for
for
Remark 1 Because
![]() , (7) generalizes (5) to the nonstationary case. If some of the differencing polynomials are unity (i.e., no differencing is required to produce a stationary series), the formula collapses down to the classical case. In the extreme case that all the series are stationary, trivially
, (7) generalizes (5) to the nonstationary case. If some of the differencing polynomials are unity (i.e., no differencing is required to produce a stationary series), the formula collapses down to the classical case. In the extreme case that all the series are stationary, trivially
![]() and
and
![]() for all times
for all times ![]() . The second expression for
the frf in (7) shows how this is a direct multivariate generalization of the univariate frf in Bell (1984), which has the formula
. The second expression for
the frf in (7) shows how this is a direct multivariate generalization of the univariate frf in Bell (1984), which has the formula
![]() .
.
Theorem 1 is worded so as to include the important case of co-integrated vector time series (Engle and Granger, 1987), as
![]() is only required to be invertible at most frequencies. We next show that the key assumptions of Theorem 1 on the structure of
is only required to be invertible at most frequencies. We next show that the key assumptions of Theorem 1 on the structure of
![]() are satisfied for a very wide class of co-integrated processes. We present our discussion in the context of uniform differencing operators - a result can be formulated for
the more general case, but it is much more difficult to state, and the uniform differencing operator situation is sufficient for most, if not all, econometric applications of interest.
are satisfied for a very wide class of co-integrated processes. We present our discussion in the context of uniform differencing operators - a result can be formulated for
the more general case, but it is much more difficult to state, and the uniform differencing operator situation is sufficient for most, if not all, econometric applications of interest.
The vector signal and noise processes satisfy
![]() and
and
![]() , and we suppose that a Wold decomposition can be found for these core processes:
, and we suppose that a Wold decomposition can be found for these core processes:
where
In order that the data core spectrum
![]() is invertible almost everywhere, it is convenient to assume that
is invertible almost everywhere, it is convenient to assume that
![]() is positive definite at all frequencies; as shown below, this is a sufficient condition. Such a noise core process is said to be invertible, by definition.
is positive definite at all frequencies; as shown below, this is a sufficient condition. Such a noise core process is said to be invertible, by definition.
Proposition 1 Suppose that the differencing operators are uniform and that the core processes follow (8). Also suppose that
![]() is invertible. Then
is invertible. Then
![]() is invertible except at a finite set of frequencies, and
is invertible except at a finite set of frequencies, and
![]() defined in (7) can be continuously extended from its natural domain
defined in (7) can be continuously extended from its natural domain ![]() to all of
to all of
![]() .
.
The argument also works with the roles of signal and noise swapped; we require that one of the core component processes be invertible. So the formula for the WK frf is well-defined - by taking the appropriate limits at the nonstationary frequencies - and (7)
can be used to give a compact expression for the filter, formally substituting ![]() for
for
![]() :
:
This expresses the filter in terms of the ACGFs of the over-differenced signal and noise processes.
We can re-express this in terms of the so-called pseudo-ACGFs of signal and noise, which are defined via
![\displaystyle \mathbf{\Gamma }_{\mathbf{s}}(L)=\mathbf{\Gamma }_{\mathbf{u}}(L){\ \left[ \widetilde{\delta }_{\mathbf{s}}(L)\widetilde{\delta }_{\mathbf{s}}(L^{-1})% \right] }^{-1}\qquad \mathbf{\Gamma }_{\mathbf{n}}(L)=\mathbf{\Gamma }_{% \mathbf{v}}(L){\ \left[ \widetilde{\delta }_{\mathbf{n}}(L)\widetilde{\delta }_{\mathbf{n}}(L^{-1})\right] }^{-1}.](img156.gif)
|
As usual, the tilde denotes a diagonal matrix; here the entries correspond to the differencing polynomials for each series. This generalizes the ACGF structure from stationary to nonstationary multivariate processes. Also
Whereas in the univariate case one can compute filter coefficients readily from the filter formula (9) - by identifying the frf as the spectral density of an associated ARMA process and using standard inverse FT algorithms - the situation is more challenging in the
multivariate case. Instead, coefficients would be determined by numerical integration. Although this may be done, for practical applications we rather recommend the exact finite sample approach of the next section. Of course, filters can be expressed for both signal and noise extraction, and
trivially by (7) the sum of their respective frfs is the identity matrix (as a function of ![]() ). This is analogous to the univariate case, where
signal and noise frfs sum to unity for all
). This is analogous to the univariate case, where
signal and noise frfs sum to unity for all ![]() .
.
3 Multivariate signal extraction from a finite sample
We now discuss multivariate signal extraction for a finite sample from a time series, and present exact matrix formulas for the solution to the problem. This represents the first treatment of the multivariate case for either the stationary or nonstationary frameworks. Even away from the end-points in a relatively long but finite sample, there is a certain attraction to having the unique optimum signal derived from the underlying theory. However, the main interest for applications like current monitoring of price trends lies in estimators near the end of series, for which the formulas give an analytical characterization and reveal the explicit dependence on series' individual parameters, on cross-relationships, and on sample size and signal location.
As in Section 2, we consider ![]() time series
time series
![]() for
for
![]() , and suppose that each series can be written as the sum of unobserved signal and noise components, denoted
, and suppose that each series can be written as the sum of unobserved signal and noise components, denoted
![]() and
and
![]() , such that (4) holds for all
, such that (4) holds for all ![]() . While in the previous section, we considered
. While in the previous section, we considered ![]() unbounded in both directions, here we suppose the time range of the sample consists of
unbounded in both directions, here we suppose the time range of the sample consists of
![]() . We will express the realizations of each series as a length-
. We will express the realizations of each series as a length-![]() vector, namely
vector, namely
![]() , and similarly for signal,
, and similarly for signal,
![]() and noise,
and noise,
![]() . For each
. For each ![]() , the optimal estimate is the conditional expectation
, the optimal estimate is the conditional expectation
![]() . As in the previous section, the definition of optimality used here is the minimum MSE
estimator under normality and the best linear estimator with non-Gaussian specifications.
. As in the previous section, the definition of optimality used here is the minimum MSE
estimator under normality and the best linear estimator with non-Gaussian specifications.
So our estimate
![]() can be expressed as a
can be expressed as a
![]() matrix acting on all the data vectors stacked up, or equivalently as
matrix acting on all the data vectors stacked up, or equivalently as
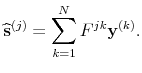 |
Each matrix
We may express the specification of the finite series in matrix notation with
![]() being a stationary vector, where
being a stationary vector, where
![]() is a
is a
![]() dimensional matrix whose rows consist of the coefficients of
dimensional matrix whose rows consist of the coefficients of
![]() , appropriately shifted. (For the treatment of the univariate case, see McElroy (2008).) The application of each
, appropriately shifted. (For the treatment of the univariate case, see McElroy (2008).) The application of each
![]() yields a stationary vector, called
yields a stationary vector, called
![]() , which has length
, which has length ![]() (so
(so
![]() ). These vectors may be correlated with one another and among themselves, which is summarized in
the notation
). These vectors may be correlated with one another and among themselves, which is summarized in
the notation
![]() . We further suppose that the differencing is taken such that all random vectors have mean zero (this
presupposes that fixed effects have been removed via regression). Note that this definition includes processes that are nonstationary only in second moments, i.e., heteroskedastic. Therefore, the setup is somewhat broader than in the previous section where the core processes were assumed covariance
stationary.
. We further suppose that the differencing is taken such that all random vectors have mean zero (this
presupposes that fixed effects have been removed via regression). Note that this definition includes processes that are nonstationary only in second moments, i.e., heteroskedastic. Therefore, the setup is somewhat broader than in the previous section where the core processes were assumed covariance
stationary.
This discussion can also be extended to the signal and noise components as follows. We form the matrices
![]() and
and
![]() corresponding to the signal and noise differencing polynomials
corresponding to the signal and noise differencing polynomials
![]() and
and
![]() Let
Let
![]() and
and
![]() , with cross-covariance matrices denoted
, with cross-covariance matrices denoted
![]() and
and
![]() . Now assume there are no common roots among
. Now assume there are no common roots among
![]() and
and
![]() , so that
, so that
![]() . Then as in the univariate case (McElroy and Sutcliffe, 2006), we have
. Then as in the univariate case (McElroy and Sutcliffe, 2006), we have
where
and hence - if
We can splice all these
Up to this point, we have set out notation and some basic working assumptions. For the signal extraction formula below, we require a few additional assumptions: let
![]() and
and
![]() be invertible matrices for each
be invertible matrices for each ![]() , assume that
, assume that
![]() and
and
![]() are uncorrelated with one another for all
are uncorrelated with one another for all ![]() , and suppose
that the initial values of
, and suppose
that the initial values of
![]() are uncorrelated with
are uncorrelated with
![]() and
and
![]() for all
for all ![]() . These initial values consist of all the first
. These initial values consist of all the first
![]() values of each sampled series
values of each sampled series
![]() . This type of assumption is less stringent than
. This type of assumption is less stringent than
![]() of the previous subsection, and will be called Assumption
of the previous subsection, and will be called Assumption ![]() instead.
instead.
Assumption 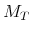 .
.
Suppose that, for each
![]() , the initial values of
, the initial values of
![]() (the first
(the first ![]() observations) are uncorrelated with
observations) are uncorrelated with
![]() and
and
![]() .
.
Since Assumption ![]() entails that the initial values of the observed process are uncorrelated with
entails that the initial values of the observed process are uncorrelated with
![]() , it implies the condition often used to give a relatively simple Gaussian likelihood. Our main result below involves block matrices, and we use the following notation. If
, it implies the condition often used to give a relatively simple Gaussian likelihood. Our main result below involves block matrices, and we use the following notation. If
![]() is a block matrix partitioned into sub-matrices
is a block matrix partitioned into sub-matrices ![]() , then
, then
![]() denotes a block matrix consisting of only the diagonal sub-matrices
denotes a block matrix consisting of only the diagonal sub-matrices ![]() , being zero elsewhere.
, being zero elsewhere.
Theorem 2 Assume that
![]() is invertible, along with all
is invertible, along with all
![]() and
and
![]() matrices, and that
matrices, and that
![]() and
and
![]() are uncorrelated with one another for all
are uncorrelated with one another for all ![]() and
and ![]() . Also suppose that Assumption
. Also suppose that Assumption ![]() holds. Let
holds. Let
Then
for
![\displaystyle \sum_{\ell,m=1}^{N}\left[ {\ \Delta _{\mathbf{n}}^{(j)}}^{\prime ... ...hbf{v}}^{mk}{\Sigma _{\mathbf{v}}^{kk}}% ^{-1}\Delta _{\mathbf{n}}^{(k)}\right]](img234.gif) |
||
A compact matrix formula for
Also let
and the covariance matrix of the error vector is
Remark 2 These formulas tell us mathematically how each series
![]() contributes to the component estimate
contributes to the component estimate
![]() . From the formulas for
. From the formulas for ![]() and
and ![]() we see that only the noise in
we see that only the noise in
![]() is differenced, while for all other series both signal and noise are differenced. When there is no cross-series information, i.e.,
is differenced, while for all other series both signal and noise are differenced. When there is no cross-series information, i.e.,
![]() and
and
![]() are zero for
are zero for ![]() , then clearly
, then clearly ![]() and
and ![]() are zero, and
are zero, and ![]() reduces to an
reduces to an ![]() -fold stacking of the univariate filter (
-fold stacking of the univariate filter (
![]() is just the stacking of the univariate matrix filters of McElroy (2008)).
is just the stacking of the univariate matrix filters of McElroy (2008)).
The matrix formula for ![]() is predicated on a specific way of stacking the time series data into
is predicated on a specific way of stacking the time series data into
![]() . This is a particularly convenient form, since each sub-matrix
. This is a particularly convenient form, since each sub-matrix ![]() can be easily peeled off from the block matrix
can be easily peeled off from the block matrix ![]() , and directly corresponds to the contribution of the
, and directly corresponds to the contribution of the ![]() th series to the signal estimate for the
th series to the signal estimate for the ![]() th series. Stacking the data in another order - e.g., with all the observations for time
th series. Stacking the data in another order - e.g., with all the observations for time ![]() together, followed by
together, followed by ![]() , etc. - would scramble the intuitive structure in
, etc. - would scramble the intuitive structure in ![]() .
.
In particular, one may pass to this alternative stacking, written as
via application of a
Let us consider any length ![]() column vector
column vector ![]() (which may be stochastic or
deterministic), consisting of
(which may be stochastic or
deterministic), consisting of ![]() subvectors
subvectors ![]() of length
of length ![]() , where
, where
![]() . Then
. Then
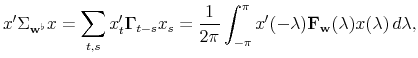 |
where
But
![]() is invertible for processes consisting of co-linear core signal and invertible core noise (or vice versa), which indicates that maximum likelihood estimation is viable;
the Gaussian log likelihood is
is invertible for processes consisting of co-linear core signal and invertible core noise (or vice versa), which indicates that maximum likelihood estimation is viable;
the Gaussian log likelihood is
up to a constant irrelevant for maximization (once we factor out the initial value vectors using Assumption
The use of these formulas have some advantages over the state space approach. Certain questions, which involve the covariances of the signal extraction error across different time points, can be directly addressed with a matrix analytical approach. Also, the expressions are of practical interest when processes cannot be embedded in State Space Form (SSF); for example, a long memory cannot be cast in this form without truncation, which radically alters the memory dynamics. Generally, so long as the covariance and cross-covariance matrices used in Theorem 3 are available, the results apply. So we may consider heteroskedastic core processes and see the exact functional dependence of the filters on each time-varying variance parameter.
Furthermore, we can estimate any linear function of the signal. Supposing that our quantity of interest is
![]() for some large matrix
for some large matrix ![]() applied to the stacked signal vector
applied to the stacked signal vector
![]() (for example,
(for example,
![]() could be the rate of change of the signal processes), then the optimal estimate for this quantity is simply
could be the rate of change of the signal processes), then the optimal estimate for this quantity is simply
![]() by the linearity of the conditional expectation (for Gaussian time series). Also, since the error covariance matrix for the estimation of
by the linearity of the conditional expectation (for Gaussian time series). Also, since the error covariance matrix for the estimation of
![]() is
is
![]() , it follows that the error covariance matrix (whose diagonals are the MSEs) for our estimate of
, it follows that the error covariance matrix (whose diagonals are the MSEs) for our estimate of
![]() is
is
![]() . Thus, for non-trivial problems a full knowledge of all the entries of
. Thus, for non-trivial problems a full knowledge of all the entries of ![]() and
and ![]() is required.
is required.
One particular case that is simple and of practical interest arises when ![]() is composed of unit vectors such that
is composed of unit vectors such that
![]() . That is, we are interested in the
. That is, we are interested in the ![]() th component of
the signal at all sampled time points. Since
th component of
the signal at all sampled time points. Since
![]() is just a projection of
is just a projection of
![]() , its extraction matrix is given by the same projection
, its extraction matrix is given by the same projection ![]() applied to
applied to
![]() . So the components of the optimal signal estimate are equal to the optimal estimates of the components of the signal (by linearity of conditional expectations).
. So the components of the optimal signal estimate are equal to the optimal estimates of the components of the signal (by linearity of conditional expectations).
4.1 Discussion of models
Since many economic time series are subject to permanent changes in level, there has been extensive research on models with stochastic trends. Models with related trends, where the underlying permanent shocks are correlated, allow us to establish links between series in their long-run behavior.
When there exists a particularly close relationship in the long-run movements across variables, as when series are co-integrated, there are some special implications for trend extraction, as we discuss later. A natural way to think about co-integration is in terms of common trends (i.e., co-linear innovations), as in Stock and Watson (1988) and Harvey (1989). A co-integrating relationship implies a tight long-run connection between a set of variables, with any short-run deviations in the relationships tending to correct themselves as time passes. Then, the long-run components of different series move together in a certain sense (there exist linear combinations of the trends that fluctuate around zero, i.e., are stationary). In the case of common trends, as demonstrated in the next sub-section, the gain functions for signal extraction have a collective structure at the frequency origin. Otherwise, in the absence of commonality, no matter how closely related the trends are, the filters decouple at the zero frequency.
As in the treatment given in Nyblom and Harvey (2000), we define the vector process
![]()
![]() as the trend,
as the trend,
![]()
![]() as the irregular, and
as the irregular, and
![]()
![]() as the observed series. Then the multivariate Local Level Model (LLM) is given by
as the observed series. Then the multivariate Local Level Model (LLM) is given by
where
For identification, the elements of the load matrix
As an I(2) process, the Smooth Trend Model (STM) specification accounts for a time-varying slope:
This formulation tends to produce a visibly smooth trend. For reduced rank
where
The multivariate model captures the crucial aspect that related series undergo similar movements; pooling series allows us to more effectively pinpoint the underlying trend of each series. Further, the multivariate models give a better description of the fluctuations in different series and so the filters' compatibility improves even more. Parameter estimates for each series improve and the new information is available for signal estimation through the estimated correlations, which discriminate between trend and stationary parts.
4.2 Gain Functions and Finite-Sample Filters
Now we present expressions for the gain functions in the bi-infinite case and for the input matrices needed for the exact filters with finite-length series. Throughout this sub-section, ![]() denotes an integer
denotes an integer![]() where
where ![]() for the LLM and
for the LLM and ![]() for the STM. Because
for the STM. Because
the quantities in the matrix formulation of Theorem 1 are
The time domain expression for the filter follows by replacing
Recall that the component functions
![]() tell us how the
tell us how the ![]() th series' dynamics are spectrally
modified in producing the
th series' dynamics are spectrally
modified in producing the ![]() th output series. The corresponding component gain functions are tied closely to the values of the variances and the correlations. Consider
th output series. The corresponding component gain functions are tied closely to the values of the variances and the correlations. Consider
![]() , or the value of the gain function at
, or the value of the gain function at
![]() ; this is of special interest, since it relates to how the very lowest frequency is passed by the filter. In the case that
; this is of special interest, since it relates to how the very lowest frequency is passed by the filter. In the case that
![]() is invertible (i.e., the related trends case - where
is invertible (i.e., the related trends case - where ![]() can be taken as an identity matrix), we easily see that
can be taken as an identity matrix), we easily see that
![]() ; in other words, related series have no impact on the low frequency parts of the filter. Note that this separation of gains only holds at
the extreme frequency of exactly zero; at all nonzero frequencies, even very low values, the frf is typically not diagonal. The basic principle is that without the deep relationship of co-integration, the filters select out various trends that eventually diverge and that become specific to each
series.
; in other words, related series have no impact on the low frequency parts of the filter. Note that this separation of gains only holds at
the extreme frequency of exactly zero; at all nonzero frequencies, even very low values, the frf is typically not diagonal. The basic principle is that without the deep relationship of co-integration, the filters select out various trends that eventually diverge and that become specific to each
series.
However, if
![]() is non-invertible, as in the common trends case, then a different situation emerges. Suppose that
is non-invertible, as in the common trends case, then a different situation emerges. Suppose that
![]() , and using (A.1) - see the proof of Proposition 2 - we obtain
, and using (A.1) - see the proof of Proposition 2 - we obtain
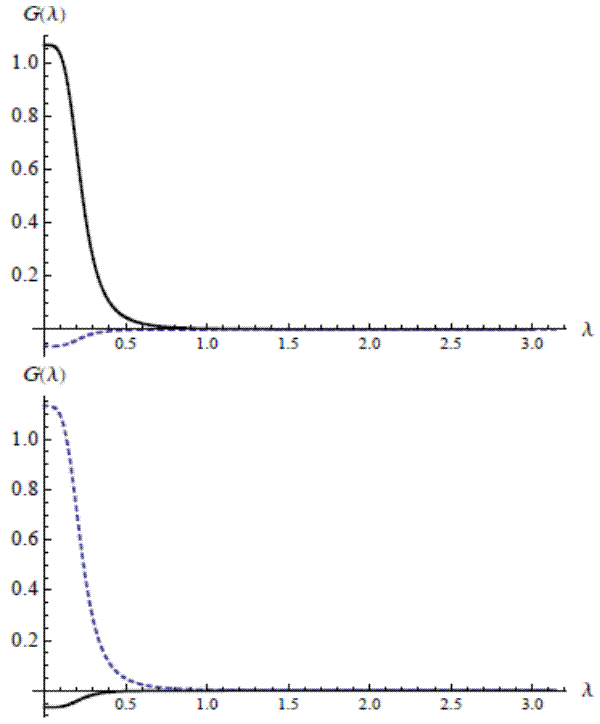
This formula reveals how the filter treats the utmost lowest-frequency components. In the special case of one common trend with
The frfs for related trends and common trends filters are similar away from frequency zero. The general situation is that
![]() for an orthogonal matrix
for an orthogonal matrix ![]() and a
diagonal matrix
and a
diagonal matrix ![]() with non-negative eigenvalues. When common trends are present, only
with non-negative eigenvalues. When common trends are present, only ![]() of these eigenvalues are nonzero. But for an irreducible related trends scenario, all
of these eigenvalues are nonzero. But for an irreducible related trends scenario, all ![]() eigenvalues are positive; in this case, we can plug
eigenvalues are positive; in this case, we can plug
![]() in for
in for
![]() in (17) to give
in (17) to give
Now let us suppose that we continuously change our related trends model to a common trends model, essentially by letting
But the treatment of frequency zero remains distinct; given the discontinuity in behavior of the frfs at the lower bound of the spectrum, which represents the longest periodicity, it becomes important to clearly differentiate between related trends and common trends. Taking the limit of the
related trends models as it tends toward a common trends model gives a different result from actually evaluating the common trends model itself. This occurs because for any invertible matrix
![]() , no matter how close it is to being non-invertible, the filter still satisfies
, no matter how close it is to being non-invertible, the filter still satisfies
![]()
The same analysis also shows that signal extraction MSE can differ somewhat between the common and related trends cases. The error spectral density is
![]() , whose average integral
equals the signal extraction MSE (the diagonals being of principal interest). But since the values at
, whose average integral
equals the signal extraction MSE (the diagonals being of principal interest). But since the values at
![]() can be quite different for the common and related trends cases - but with similarity elsewhere if correlations are close to full - the resulting MSEs need not be the same. Due
to the continuity of these functions in
can be quite different for the common and related trends cases - but with similarity elsewhere if correlations are close to full - the resulting MSEs need not be the same. Due
to the continuity of these functions in ![]() , no matter how close the related trends eigenvalues are to zero, the common trends frf will differ from the related trends frf in a
neighborhood of frequency zero, yielding a discrepancy in their integrals (we have verified this numerically).
, no matter how close the related trends eigenvalues are to zero, the common trends frf will differ from the related trends frf in a
neighborhood of frequency zero, yielding a discrepancy in their integrals (we have verified this numerically).
Therefore, it is important to use the exact common trends formulation in Theorem 1 when this case applies, and not approximate with a close related trends formulation, when computing gain functions or signal extraction MSE. Similar observations hold for finite-sample MSEs derived from Theorem 3: small discrepancies arise between the common trends case and the related trends case with very high correlation.
Moving to the analytical finite-length filters, the covariance matrices needed in Theorem 3 are
where
where the matrices
Also, (18) and (19) allow us to compute the signal extraction quantities of Theorem 3. Details are omitted here, but R code that provides both the exact Gaussian likelihood and the filter and error covariance
matrices ![]() ,
, ![]() , and
, and ![]() is available from the authors.
is available from the authors.
4.3 Inflation co-movements and trend estimation
The models discussed in the previous sub-section provide useful starting points for developing UC models and trend estimators for the core and total US inflation time series. While considerable work has been done on extensions of the univariate model such as stochastic volatility (see Stock and Watson (2007) or richer stationary dynamics around the trend (e.g., Cogley and Sbordone (2008)), we do not address these model aspects here because our principal goal is to illustrate the multivariate extension of the signal extraction framework with integrated series. The basic stochastic trend specifications already give the main insights about mutually consistent modelling and signal estimation for a set of related nonstationary variables: the role of trend behavior, of series-specific parameters, and of component correlations across series. Richer models and filters have the same essential foundation - the nonstationary part often represents the most crucial part of the design - but with more subtle dependencies or more inter-relationships and more parameters. Also, for our particular example of US inflation over the last twenty five years or so, the basic models already give a decent statistical representation, as evidenced in our results.
To the extent it represents the rate at which inflation is likely to settle moving forward, trend inflation is worth monitoring by central banks and could even be a significant factor in monetary policy deliberations. In a time series framework, we can set up an explicit model containing a trend, specified as a stochastic process with permanent changes, and an additional component reflecting short-term and less predictable variation. One advantage of such a framework is that, with a flexible modeling approach and loose constraints on its structure and parameters, we may tailor the model to the data of interest, making it consistent with their dynamic behavior and suitable for estimating useful signals both historically and currently. A model with stochastic trend also gives a convenient way to describe properties like inflation persistence (as mentioned in Cogley and Sbordone (2008), for instance), as the permanent component evolves slowly over time.
Here, we focus on the trend in total inflation as our measure of the underlying rate since the total includes the full expenditure basket, including items like gasoline, of the representative consumer. For clarity, we use "core inflation" to refer specifically to inflation for all products
excluding food and energy goods. In other usage, the term "core" inflation has sometimes been used interchangeably with "trend" inflation, the idea being that simply stripping out two of the most volatile components in inflation already gives a better representation of long-run signal. However,
equating core with trend neglects the important role of food and energy costs for the typical household, and it fails to account for the presence of both long-term and short-term movements in core as well as total. With much of the irregular component removed, the core index has additional
information, which we can use in the framework of a bivariate time series model to improve the trend estimator in total inflation. In terms of notation, we consider ![]() with core and total
arranged in the observation vector with core being the first element, and let
with core and total
arranged in the observation vector with core being the first element, and let ![]() denote the correlation across series for a given component; for example,
denote the correlation across series for a given component; for example,
![]() is the correlation between the irregulars in the core and total series.
is the correlation between the irregulars in the core and total series. ![]() The common trend specification has
The common trend specification has ![]() ; for identification, we take the base trend to represent that of core inflation, with the load matrix taking the form
; for identification, we take the base trend to represent that of core inflation, with the load matrix taking the form
![]() where the scalar
where the scalar ![]() gives the coefficient in the
linear mapping from trend core to trend total.
gives the coefficient in the
linear mapping from trend core to trend total.
The models used here generalize some previous treatments. Cogley (2002) uses a univariate version of a specific model used here. Kiley (2008) considers a bivariate common trend model with a random walk and with the loading factor constrained to unity. Here, we consider two possible trend specifications, relax the assumption of perfect correlation, and in the common trends form, allow the loading factor to be unrestricted. While it seems entirely reasonable that the trends in core and total are closely related (both because the core is a large fraction of the total basket of goods and because it is well known that price changes for the food and energy group are dominated by temporary factors), whether there are correlated or common trends is essentially an empirical question; setting up appropriately constructed models and fitting them to the data provides a coherent basis for addressing this question and for measuring the correlations between both trend and noisy movements as parameters. Finally, restricting the load parameter to one implies that core and total inflation trends are identical, which is not necessarily true given the share of food and energy in the total index and a possible stochastic trend in the food and energy portion, in general having different properties from the core trend.
We use inflation rates based on the price index for personal consumption expenditures (PCE). Core and total PCE inflation represent widely referenced data in research studies and current reports, and they are included in the economic projections of FOMC meeting participants. In considering the
welfare of society, total PCE inflation gives a valuable measure, intended to capture cost changes for the actual consumption basket of the population. The base data are the quarterly indices for total and core PCE prices from 1986Q1 to 2010Q4 (Source: Bureau of Economic Analysis). Inflation is
defined as
![]() for price index
for price index ![]() . Inflation fluctuations
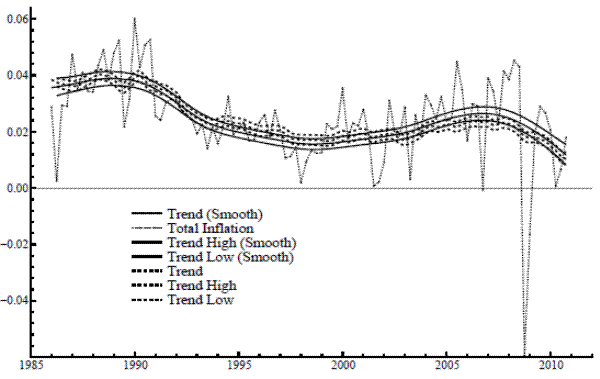
appear to have a different structure prior to the sample used here; for example, as apparent in Figure 1, there is no episode, post-mid 80s, comparable to the Great Inflation of the 70s and early 80s. Following this time of high levels and volatile movements, inflation seems to have settled into a
different pattern of variation, with a more stable level and with temporary components tending to dissipate rapidly. Economists have discussed various reasons for this new regime, such as a more effective anchoring of inflation expectations.
. Inflation fluctuations
appear to have a different structure prior to the sample used here; for example, as apparent in Figure 1, there is no episode, post-mid 80s, comparable to the Great Inflation of the 70s and early 80s. Following this time of high levels and volatile movements, inflation seems to have settled into a
different pattern of variation, with a more stable level and with temporary components tending to dissipate rapidly. Economists have discussed various reasons for this new regime, such as a more effective anchoring of inflation expectations.
We estimate the models by Maximum Likelihood3. Though the computation of the likelihood relies on Gaussian distributions, the assumption of normality is actually not needed for the efficiency of the resulting MLEs; see Taniguchi and Kakizawa (2000). With the model cast in state space, the likelihood is evaluated for each set of parameter values using the prediction error decomposition from the Kalman filter; see Harvey (1989) or Durbin and Koopman (2001). The parameter estimates are computed by optimizing over the likelihood surface. Programs were written in the Ox language (Doornik, 1998) and included the Ssfpack library of state space functions (Koopman et. al., 1999) for parameter estimation routines.
Local level results are in Table 1 for the univariate case. While the value of
![]() has a similar magnitude for core and total, the variance of the irregular is far larger for total inflation. The application of the signal extraction formulas, given the
estimated parameters, yields the trends shown in Figure 1. The confidence bands around the trends represent one standard deviation above and below the conditional expectation - the point estimate - taken at all time periods. Each trend meanders throughout the sample, its basic level evolving slowly
over the sample period, and it also undergoes frequent and subtle adjustments on a quarterly basis (due to scaling, this is more evident in the graph for core). Such an adaptive level seems reasonable to the extent that underlying inflation is affected by factors that are constantly changing. The
signal-noise ratio
has a similar magnitude for core and total, the variance of the irregular is far larger for total inflation. The application of the signal extraction formulas, given the
estimated parameters, yields the trends shown in Figure 1. The confidence bands around the trends represent one standard deviation above and below the conditional expectation - the point estimate - taken at all time periods. Each trend meanders throughout the sample, its basic level evolving slowly
over the sample period, and it also undergoes frequent and subtle adjustments on a quarterly basis (due to scaling, this is more evident in the graph for core). Such an adaptive level seems reasonable to the extent that underlying inflation is affected by factors that are constantly changing. The
signal-noise ratio
![]() indicates the relative variability of trend and noise (for a given model structure). The value of
indicates the relative variability of trend and noise (for a given model structure). The value of ![]() reported in the table is much greater for core; this contrast gives a precise statistical depiction and quantifies the informal expression that "core inflation has more signal".
reported in the table is much greater for core; this contrast gives a precise statistical depiction and quantifies the informal expression that "core inflation has more signal".
Table 1 also reports three measures of performance and diagnostics. Analogous to the usual regression fit, ![]() is the coefficient of determination with respect to first differences;
the values in the table indicate that a sizeable fraction of overall variation is explained by the models beyond a random walk, especially for total, where the extraction of the more volatile irregular in producing the trend leads to a favorable fit. The Box-Ljung statistic
is the coefficient of determination with respect to first differences;
the values in the table indicate that a sizeable fraction of overall variation is explained by the models beyond a random walk, especially for total, where the extraction of the more volatile irregular in producing the trend leads to a favorable fit. The Box-Ljung statistic ![]() is based on the first
is based on the first ![]() residual autocorrelations; here
residual autocorrelations; here ![]() . The degrees of freedom for the chi-squared distribution of
. The degrees of freedom for the chi-squared distribution of ![]() is
is ![]() , where
, where ![]() is the number of model parameters, so the 5% critical value for
is the number of model parameters, so the 5% critical value for
![]() is about 16.9. Core and total inflation have roughly equivalent values of
is about 16.9. Core and total inflation have roughly equivalent values of ![]() clearly below the 5% cutoff. The trade-off between fit and parsimony is expressed in the Akaike Information Criterion (AIC), defined by
clearly below the 5% cutoff. The trade-off between fit and parsimony is expressed in the Akaike Information Criterion (AIC), defined by
![]() where
where
![]() is the maximized log-likelihood - see (12).
is the maximized log-likelihood - see (12).
The set of results for the bivariate case, shown in Table 2, confirm the utility of including the core inflation series in the model. Relative to univariate, the ![]() statistic for total
declines modestly for the bivariate model, while the coefficient of determination rises significantly, with
statistic for total
declines modestly for the bivariate model, while the coefficient of determination rises significantly, with
![]() now measuring over 35% for total inflation. Shared parameters are shown in Table 2b; the close connection between the two series mainly appears in the trends, for which the
correlation between the disturbances is estimated as unity. The cross-correlation for the irregulars takes on a smaller positive value of about
now measuring over 35% for total inflation. Shared parameters are shown in Table 2b; the close connection between the two series mainly appears in the trends, for which the
correlation between the disturbances is estimated as unity. The cross-correlation for the irregulars takes on a smaller positive value of about
![]() . As the perfect correlation condition holds, we may directly reformulate the model as having a single common trend. As reported in Table 2b,
. As the perfect correlation condition holds, we may directly reformulate the model as having a single common trend. As reported in Table 2b, ![]() is somewhat less than one; the AIC decrease reflects the reduction in the number of parameters (values of AIC can be used to compare common and related trends models for either the LLM or STM,
but cannot be used to compare an LLM to an STM, because they have different orders of integration.) Figure 2 shows the resulting trend in total inflation and compares it with the univariate output. The solid lines pertain to the bivariate estimates. There are noticeable differences in both the
trajectory of the bivariate trend and in the substantially reduced degree of uncertainty associated with its estimation.
is somewhat less than one; the AIC decrease reflects the reduction in the number of parameters (values of AIC can be used to compare common and related trends models for either the LLM or STM,
but cannot be used to compare an LLM to an STM, because they have different orders of integration.) Figure 2 shows the resulting trend in total inflation and compares it with the univariate output. The solid lines pertain to the bivariate estimates. There are noticeable differences in both the
trajectory of the bivariate trend and in the substantially reduced degree of uncertainty associated with its estimation.
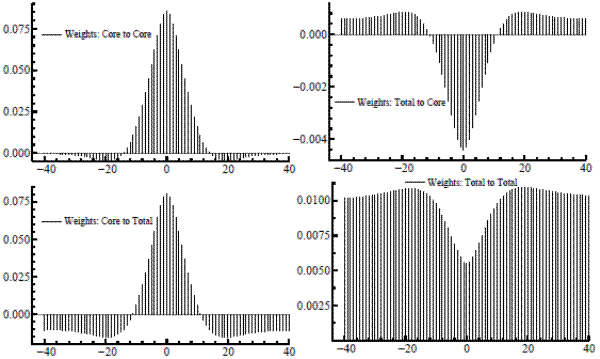
We can now use our signal extraction results to show how the model-based estimator makes optimal use of the information that core inflation gives about the trend in total. The filters, estimated from the model and applied to bivariate dataset, have coefficients in the form of ![]() weight matrices. An equivalent formulation expresses the bivariate filter as a
weight matrices. An equivalent formulation expresses the bivariate filter as a ![]() matrix of scalar filters of the usual form; for each element, figure 3 plots each filter weight against the time separation between weighted observation and signal location. The core-to-core weighting pattern in the upper-left box nearly matches the decay pattern of an
exponential on each side (there is a slight discrepancy as the weights dip just below zero at the ends). Apart from a very slight constant offset, the weights for total-to-core seem to follow a negative double exponential. Therefore, the current and adjacent values of core inflation are somewhat
overweighted, with a modestly-valued moving average of total inflation subtracted. (The small constant offset is due simply to the linear relationship between the two trends.) The bottom-left box shows the core-to-total weights, also resembles a shifted double exponential (with a slightly reduced
maximum, compared to core-to-core, to dampen the trend variability a bit). A negative offset is now readily apparent, with the weights going negative after five lags or so, again, from the linear linkage. This kernel is then set against a total-to-total pattern which, like the total-to-core cross
filter, has the shape of an inverted double exponential, adjusted by a fixed amount.
matrix of scalar filters of the usual form; for each element, figure 3 plots each filter weight against the time separation between weighted observation and signal location. The core-to-core weighting pattern in the upper-left box nearly matches the decay pattern of an
exponential on each side (there is a slight discrepancy as the weights dip just below zero at the ends). Apart from a very slight constant offset, the weights for total-to-core seem to follow a negative double exponential. Therefore, the current and adjacent values of core inflation are somewhat
overweighted, with a modestly-valued moving average of total inflation subtracted. (The small constant offset is due simply to the linear relationship between the two trends.) The bottom-left box shows the core-to-total weights, also resembles a shifted double exponential (with a slightly reduced
maximum, compared to core-to-core, to dampen the trend variability a bit). A negative offset is now readily apparent, with the weights going negative after five lags or so, again, from the linear linkage. This kernel is then set against a total-to-total pattern which, like the total-to-core cross
filter, has the shape of an inverted double exponential, adjusted by a fixed amount.
The gain functions (for the hypothetical, doubly infinite series) are shown in figure 4. The filter for core-to-core has the usual shape of a low-pass filter, representing a standard focus on low frequencies. The gradual decay of the core-to-core low-pass results from the slow decline of the trend pseudo-spectrum and its overlap with the flat spectrum of the white noise irregular. The gain rises modestly above unity at the low end, indicating a small expansion of amplitudes. Correspondingly, the cross-gain for total-to-core is less than or equal to zero everywhere, reflecting an opposite effect due to total inflation.
As the major portion of the trend in total is assessed by smoothing the core rate, this leads to a core-to-total filter that also resembles a low-pass filter. Now the gain reaches a maximum somewhat below unity, so the filter diminishes slightly the strength of the trend core movements; this contribution is then combined with another reflected (about the frequency-axis) low-pass filter applied to total.
For the smooth trend model, given in (15), the direction adjusts gradually, suggesting slowly changing long-run factors. While the smooth trend model has been successfully applied in research such as Harvey and Trimbur (2003), who examine cycles and trends in economic activity series, the multivariate smooth trends model has not yet been used for inflation data. Now, the specification allows trend inflation to increase or decrease going forward, with the rate of change subject to permanent shocks, whereas the local level model simply projects the current level ahead. As a result, it gives scope for a different view of trend inflation connected to most significant and long-run transitions in the rate over the sample period.
The results, shown in Tables 3 and 4, indicate the smooth trend as another effective tool for inflation, as there is little difference in the fit measure and diagnostics relative to the local level model. There is again a clear improvement in the fit and residual serial correlation in moving to the bivariate model. For the I(2) model, the trends in Figure 5 show stable variation for which the major trending phases and turning points become clearer, than for the more reactive local level. Basically, the estimated trend of the I(2) model concentrates on the lowest frequency, major transitions, for instance, the persistent rise in trend inflation moving into the mid-2000's, followed by stalled gains and a peak during 2007.
The correlation between the slope disturbances is unity, signifying a very close connection. as the pace of adjustment of trend moves together for core and total. Figure 6 contrasts the resulting trend with the univariate output. The solid lines, which show the estimates and confidence bands,
indicate that the path of the bivariate trend exhibits somewhat more variation over the sample and is estimated with greater precision. The associated common trend model has the form of (16) with the loading on core normalized to one and a load parameter ![]() applied to total. The reported value of
applied to total. The reported value of ![]() is close to one. The weighting
kernels for this case are shown in Figure 7. Compared to the local level case, the trend weights for core-to-core are spread over a longer range, with a slower rate of decay with lag length. This difference in weighting pattern gives rise to the smoother trend. As before, a weighted average
(offset) of the total inflation series is subtracted from smoothed core inflation (also offset) to form the trend estimate in each series.
is close to one. The weighting
kernels for this case are shown in Figure 7. Compared to the local level case, the trend weights for core-to-core are spread over a longer range, with a slower rate of decay with lag length. This difference in weighting pattern gives rise to the smoother trend. As before, a weighted average
(offset) of the total inflation series is subtracted from smoothed core inflation (also offset) to form the trend estimate in each series.
From the frequency domain perspective, the persistence in the direction of the trend and its relative smoothness result from greater concentration on low frequencies than for the random walk trend. The resulting set of low-pass filters for the smooth trend model is shown in figure 8. For both series, the gain applied to core inflation cuts off more sharply than the gains in figure 4, and this contribution is set against a negative gain, operating on total inflation, that also falls to near zero more rapidly. The greater effectiveness of the gain in cutting out high frequencies leads to the contrast in visual properties of the smooth trend compared to the local level case, as indicated in figure 9.
The formulas presented above reveal analytically how to make the most efficient use of series with high relative signal content, whose components correlate with the target's. The substantially higher signal-noise ratio of core, and to some extent also the positive irregular correlation, affects the filter design. A pronounced focus on core, which is actually over-weighted and compensated for by subtracting some signal in total, appears to help avoid large errors in favor of more frequent smaller errors in the signal extraction (as the estimator satisfies the minimum MSE optimality criterion).
Compared to a simple reliance on core, the optimal measurement of trend has some basic differences. In both the local level and smooth trend cases, the estimation of each trend starts with the extraction of noise from core. To extract the trend in total inflation, although the emphasis remains on core, a different moving average is applied to the core rate (adjusted by a linear function compared to the weights for computing core trend), which is then set against a modest weighted average of the total rate. So, the measurement of total's trend relies also to some extent on total (and likewise for the trend in core). Our example with trend inflation illustrates how the possibility of contrasting trend structures, different properties of individual series, and linkages across series, together exert important effects on the weight and gain patterns for signal estimation.
While our illustrations have used simple stochastic trend plus noise models, they already show that the exact optimal weighting of just two series has non-obvious aspects such as a slight over-emphasis on the signalling series compensated by subtracting a weighted average of the noisier target. When using more complex specifications to generate even more refined trend estimates, while the set of determinants would expand to include, for instance, variance-ratios involving disturbances for other components such as cycles, one would encounter the same essential issues as in our illustration. The precise way to best combine two or more series with variable signal content, that may have multiple components, depends now on the matrix structures expressing the complete set of dynamic relationships. Our new results allow us to solve the general formulation of such problems explicitly, that would either lie outside our ability to intuit the optimal extraction of the signal or where reliance on intuition alone would lead to inefficient use of the available data (and would preclude knowledge of the probable error or of the uncertainty in our estimates).
5 Conclusions
Applications of signal extraction intertwines with areas like current analysis, policy-making, and forecasting; in this context, multivariate frameworks may yield more informed and accurate estimates of components of interest, while incorporating more of the available information in the form of additional series and their cross-relationships. Often the economic data involved show nonstationary behavior, and the related stochastic trends across series represent a primary signal of interest, whose estimation also substantially influences the measurement of any other components present in the series.
Here, we have generalized the well-known Wiener-Kolmogorov formula to the situation of interest in econometrics, which represents a key theoretical foundation and allows us to derive new results on signal estimation for multiple economic time series. The effective modelling of co-movements across related time series has been the subject matter of some of the major ongoing developments in econometrics in statistics, and correspondingly, a wide range of multivariate signal extraction systems appear in economics and other fields. The contributions of this paper substantially extend our understanding of such problems; now we can examine the analytical expressions for the optimal set of weight polynomials, applied to the observation vectors, based on the matrix ACGFs or pseudo-ACGFs. The bi-infinite analysis shows, in compact form, precisely how to best use the new information, in addition to the component relationships in the signal's own reference series, to construct estimates. When series with high signal content are readily available, as in the total-core inflation example, we can derive the adjustment and shifting of model-based weightings on the observations, quantifying how it depends on the cross-correlations and variances. This mathematical precision, together with the accompanying insight and knowledge about the signal estimation, may provide the basis for improved treatment of and better understanding of existing contexts. Our formulas also allow us to derive new signal estimators for multiple nonstationary time series, expanding the scope of methodology in economics and other fields.
The finite sample time-domain formulas, which we have used for the actual application of the filters, account for the dependence of the correct optimal filters on series length and signal location. The new theoretical content consists of general analytical expressions for weight patterns, that reveal precisely how series length, signal location, and parameters (including those governing dynamic linkages among series) jointly affect the estimators. From a methodological perspective, our contribution expands the array of available computational strategies, in particular the widely used state space approach. The direct matrix approach includes extensions, such as long-memory, not easily handled in state space. As another example, it allows us to explore signal extraction theory in the presence of time variation in variances - a model aspect of extensive interest in the time series literature - in the multivariate extension to McElroy (2008), who showed initial results for the univariate case.
While our results cover ground complementary to the state space approach, our method offers a different, direct route to calculation (results in Bell and Hillmer (1991) indicate that a correctly initialized Kalman filter will produce Gaussian conditional expectations that are in agreement with standard initial values assumptions such as those made in this paper). The complete functional form of the optimal asymmetric filters for multiple series may also prove useful toward improving practice, as, for instance, signal detection properties toward the end of the available data remain of considerable importance for researchers and, perhaps, policymakers. The method can also readily produce useful additional information, e.g., quantities like signal velocity, or rates of change. As another example, we may examine signal estimation diagnostics that indicate performance in this context, analogous to statistical measures for specification tenability in a model comparison context.
In addition to providing the base for eliciting movements of interest (or certain properties of these movements), signal-noise structures also represent candidate classes of time series models, useful for the typical problems like historical summary and interpretation and explanatory analysis as well as forecasting. These formulations offer useful windows into patterns in fluctuations, and we can handle co-integration with common driving forces for the stochastic trends or analogously, linked stationary, serially correlated elements in groups of series. So we can unify modelling, descriptive analysis, and forecasting with signal extraction frameworks, including classic ones - connected to the kind of macroeconomic story-telling useful for discussions among economists and policy-makers - like those used to estimate trends (such as potential output or the NAIRU) or business cycle components.
Based on the core property of optimality and adaptability to time series dynamics, our contributions provide a cornerstone for signal extraction theory and estimator design in econometrics: completing a well-known line of contributions (Wiener (1949), Whittle (1963), and Bell (1984)) and generalizing the matrix method, a direct alternative to the popular state space approach with new theoretical content for finite samples. As the formulations we consider include highly general multivariate specifications for nonstationary sets of time series, our results have a broad scope and allow for comprehensive development and investigation of a very wide range of situations, including advances in existing areas like trend analysis, as well as new signal extraction architectures that may emerge from future research and experience with economic fluctuations.
A. Proof of Theorem 1
. The action of each filter on a time series is obtained by replacing ![]() by
by ![]() and
and
![]() by
by ![]() . The error process is defined via
. The error process is defined via
![]() . (It is also easy to derive an expression for
. (It is also easy to derive an expression for
![]() , which has the same formula as (6) but with signal and noise swapped.) Then applying (6) to this
error decomposition yields
, which has the same formula as (6) but with signal and noise swapped.) Then applying (6) to this
error decomposition yields
One can swiftly see the stationarity of the error process, as well as its orthogonality to
Under the assumption that the differencing operators are uniform, we have (since diagonal matrices commute with any other matrix)
Using this relation produces
Similar substitutions in the error spectral density produce, after much algebra, the stated formula.
B. Proof of Proposition 1.
The spectral density of the differenced data process is
![\displaystyle = q^{-1} (\lambda) { \left[ \Omega (z) \Sigma_{\bf\kappa} \Omega^{\prime} (\overline{z}) \right] }^{-1} - \frac{ p (\lambda) }{ q (\lambda) } { \left[ \Omega (z) \Sigma_{\bf\kappa} \Omega^{\prime} (\overline{z}) \right] }^{-1} \Xi (z) \Theta \Sigma_{\bf\eta}](img438.gif) |
||
![\displaystyle \cdot { \left\{ q (\lambda) 1_N + p(\lambda) \Theta^{\prime} \Xi^{\prime} (\overline{z}) { \left[ \Omega (z) \Sigma_{\bf\kappa} \Omega^{\prime} (\overline{z}) \right] }^{-1} \Xi (z) \Theta \Sigma_{\bf\eta} \right\} }^{-1}](img439.gif) |
||
This formula is quite informative: the above derivation shows that
However, the frf (7) for any ![]() such that
such that
![]() is given by
is given by
![\displaystyle = p (\lambda) \Xi (z) \Theta \Sigma_{\bf\eta} \cdot { \left\{ q (\lambda) 1_N + p(\lambda) \Theta^{\prime} \Xi^{\prime} (\overline{z}) { \left[ \Omega (z) \Sigma_{\bf\kappa} \Omega^{\prime} (\overline{z}) \right] }^{-1} \Xi (z) \Theta \Sigma_{\bf\eta} \right\} }^{-1}](img446.gif) |
||
and the limit as
![\displaystyle = p (\lambda_s) \Xi (z_s) \Theta \Sigma_{\bf\eta} \cdot { \left\{ p(\lambda_s) \Theta^{\prime} \Xi^{\prime} (\overline{z_s}) { \left[ \Omega (z_s) \Sigma_{\bf\kappa} \Omega^{\prime} (\overline{z_s}) \right] }^{-1} \Xi (z_s) \Theta \Sigma_{\bf\eta} \right\} }^{-1}](img451.gif)
Now let us treat the case that the innovations are not co-linear, and yet
C. Proof of Theorem 2.
The invertibility of each ![]() follows from the univariate argument in McElroy (2008), using the fact that
follows from the univariate argument in McElroy (2008), using the fact that
![]() and
and
![]() share no common factors. The signal error for the
share no common factors. The signal error for the ![]() th
signal is
th
signal is
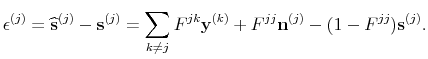
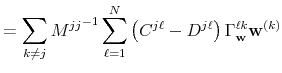 |
||
Next, we show that the covariance between this error vector and each
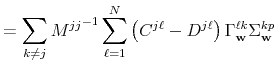 |
||
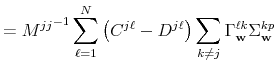 |
||
Consider the first term. By the definition of
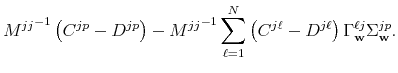
To prove the matrix form of the results, note that the ![]() th block matrix of the putative formula for
th block matrix of the putative formula for ![]() is
is
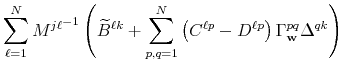 |
||
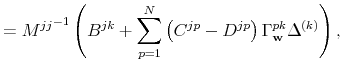 |
using the block-diagonal structure of
Acknowledgements Thanks to participants at the NBER/NSF time series conference, held at Michigan State University in September 2011, as well as those who attended the College Park seminar in October 2011 and the FRB seminar in November 2011. Thanks in particular to William Bell, Scott Holan, Ben Kedem, Seth Pruitt, Elmar Mertens, Barbara Rossi, Jeremy Rudd, Aaron Smith and Marc Wildi for helpful discussion.
|
|
|
|
||||
| Core | 5.82e-006 | 1.77e-005 | 0.329 | 0.164 | 13.42 | -750.96 |
| Total | 7.41e-006 | 0.000172 | 0.0431 | 0.261 | 13.26 | -559.01 |
Results for sample period 1986Q1 to 2010Q4 for models of the form (13) with
![]() . The parameter
. The parameter
![]() corresponds to the variance of the trend disturbance, in this case a level disturbance, and
corresponds to the variance of the trend disturbance, in this case a level disturbance, and
![]() is the irregular variance;
is the irregular variance;
![]() is the signal-noise ratio .
is the signal-noise ratio .
![]() is the coefficient of determination with respect to first differences, and
is the coefficient of determination with respect to first differences, and
![]() is the Box-Ljung statistic based on the first
is the Box-Ljung statistic based on the first
![]() residual autocorrelations.
residual autocorrelations.
![]() is the Akaike Information Criterion, given by
is the Akaike Information Criterion, given by
![]() log
log
![]() where log
where log
![]() is the maximized log-likelihood.
is the maximized log-likelihood.
|
|
|
|
|||
| Core | 5.18946e-006 | 1.84607e-005 | 0.281 | 0.179 | 11.08 |
| Total | 3.66532e-006 | 0.000177859 | 0.0206 | 0.3552 | 12.77 |
Results for sample period 1986Q1 to 2010Q4 for a model of the form (13) with
![]() . For the series indicated in the left-most column, the parameter
. For the series indicated in the left-most column, the parameter
![]() corresponds to the variance of the level disturbance and
corresponds to the variance of the level disturbance and
![]() is the irregular variance;
is the irregular variance;
![]() is the signal-noise ratio .
is the signal-noise ratio .
![]() is the coefficient of determination with respect to first differences, and
is the coefficient of determination with respect to first differences, and
![]() is the Box-Ljung statistic based on the first
is the Box-Ljung statistic based on the first
![]() residual autocorrelations.
residual autocorrelations.
|
|
|
|||
| 1.000 | 0.49832 | -1349.25 | 0.840 | -1351.25 |
Results for sample period 1986Q1 to 2010Q4 for a model of the form (13) with
![]() . The parameter
. The parameter
![]() corresponds to the correlation between the level disturbances in the two series, and
corresponds to the correlation between the level disturbances in the two series, and
![]() is the irregular variance.
is the irregular variance.
![]() is given by
is given by
![]() log
log
![]() where log
where log
![]() where log
where log
![]() is the maximized log-likelihood.
is the maximized log-likelihood.
![]() (Related) is the Akaike Information Criterion for (13) where
(Related) is the Akaike Information Criterion for (13) where
![]() is an estimated parameter. For the common levels form, (14),
is an estimated parameter. For the common levels form, (14),
![]() is the load factor, applied to the trend in core, that gives the trend in total;
is the load factor, applied to the trend in core, that gives the trend in total;
![]() (Common) is the Akaike Information Criterion of the model.
(Common) is the Akaike Information Criterion of the model.
|
|
|
|
||||
| Core | 6.36e-008 | 2.33e-005 | 0.00273 | 0.133 | 16.37 | -748.82 |
| Total | 6.17e-008 | 0.000185 | 0.000334 | 0.22 | 12.64 | -555.06 |
Results for sample period 1986Q1 to 2010Q4 for models of the form (15) with
![]() . The parameter
. The parameter
![]() is the slope disturbance variance parameter, and
is the slope disturbance variance parameter, and
![]() is the irregular variance;
is the irregular variance;
![]() is the signal-noise ratio .
is the signal-noise ratio .
![]() is the coefficient of determination with respect to first differences, and
is the coefficient of determination with respect to first differences, and
![]() is the Box-Ljung statistic based on the first
is the Box-Ljung statistic based on the first
![]() residual autocorrelations.
residual autocorrelations.
![]() is the Akaike Information Criterion, given by
is the Akaike Information Criterion, given by
![]() log
log
![]() where log
where log
![]() is the maximized log-likelihood.
is the maximized log-likelihood.
|
|
|
|
|||
| Core | 6.11564e-008 | 2.34043e-005 | 0.00261 | 0.1462 | 15.3 |
| Total | 6.89953e-008 | 0.000179544 | 0.000384 | 0.3457 | 14.07 |
Results for sample period 1986Q1 to 2010Q4 for a model of the form (15) with
![]() . For the series indicated in the left-most column, the parameter
. For the series indicated in the left-most column, the parameter
![]() corresponds to the variance of the slope disturbance and
corresponds to the variance of the slope disturbance and
![]() is the irregular variance;
is the irregular variance;
![]() is the signal-noise ratio .
is the signal-noise ratio .
![]() is the coefficient of determination with respect to first differences, and
is the coefficient of determination with respect to first differences, and
![]() is the Box-Ljung statistic based on the first
is the Box-Ljung statistic based on the first
![]() residual autocorrelations.
residual autocorrelations.
|
|
|
|||
| 1.000 | 0.513972 | -1332.06 | 1.06219 | -1334.06 |
Results for sample period 1986Q1 to 2010Q4 for a model of the form (15) with
![]() . The parameter
. The parameter
![]() corresponds to the correlation between the slope disturbances in the two series, and
corresponds to the correlation between the slope disturbances in the two series, and
![]() is the irregular variance.
is the irregular variance.
![]() is given by
is given by
![]() log
log
![]() where log
where log
![]() where log
where log
![]() is the maximized log-likelihood.
is the maximized log-likelihood.
![]() (Related) is the Akaike Information Criterion for (15) where
(Related) is the Akaike Information Criterion for (15) where
![]() is an estimated parameter. For the common slopes form, (16),
is an estimated parameter. For the common slopes form, (16),
![]() is the load factor, applied to the trend in core, that gives the trend in total;
is the load factor, applied to the trend in core, that gives the trend in total;
![]() (Common) is the Akaike Information Criterion of the model.
(Common) is the Akaike Information Criterion of the model.
Figure 1: Trend estimates, Univariate Local Level Model, for core and total PCE inflation. Sample is 1986Q1 to 2010Q4
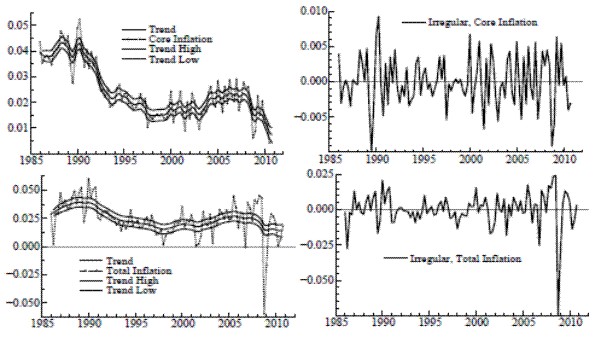
Figure 2: Trend estimates, Univariate and Bivariate Local Level Model, for total PCE inflation. Sample is 1986Q1 to 2010Q4
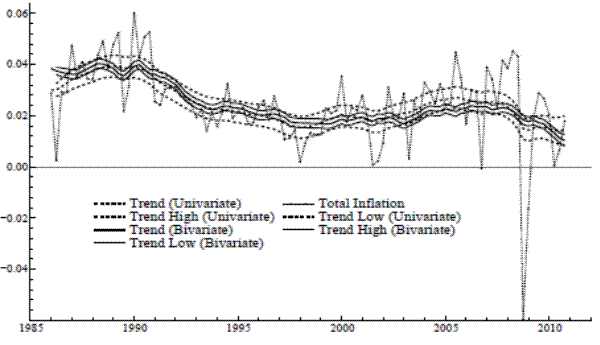
Figure 3: Observation weights for estimating trends in core inflation and total inflation for the local level model.
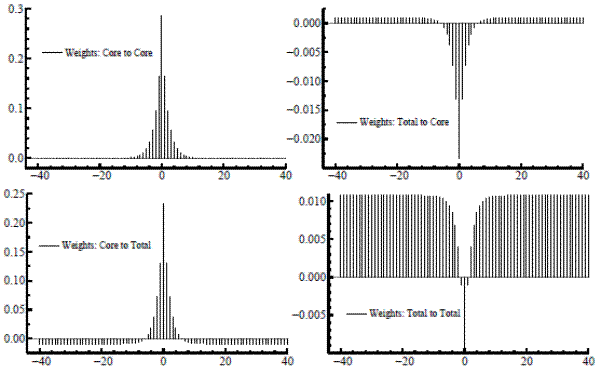
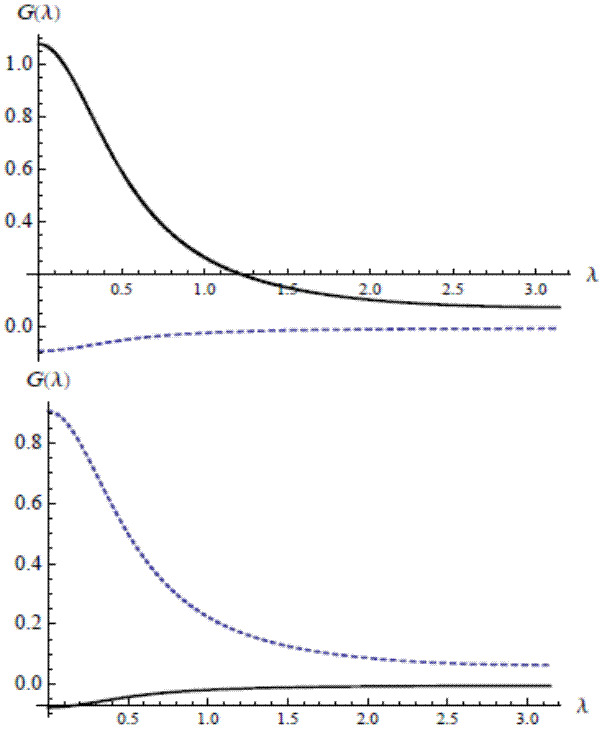
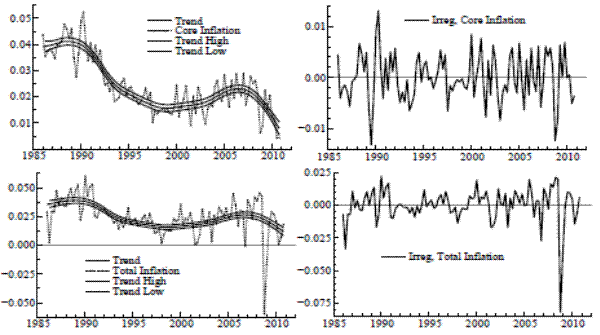
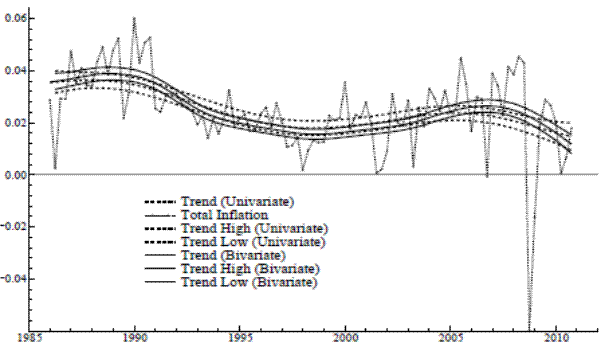
Figure 7: Observation weights for estimating trends in core and total inflation for the smooth trend model.