FEDS Notes
December 06, 2024
Using Generative AI Models to Understand FOMC Monetary Policy Discussions
Wendy Dunn, Ellen E. Meade, Nitish Ranjan Sinha, and Raakin Kabir
Introduction
In an era increasingly shaped by artificial intelligence (AI), the public's understanding of economic policy may be filtered through the lens of generative AI models (also called large language models or LLMs). Generative AI models offer the promise of quickly ingesting and interpreting large amounts of textual information. Thus far, however, little is known about how well these technologies perform in an economic policy setting.
In this note, we report on our investigation into the ability of several off-the-shelf generative AI models to identify topics discussed during monetary policy deliberations from the published Federal Open Market Committee (FOMC) meeting minutes, a key communication channel between policymakers and the public. Even though most central banks are not using generative AI in developing their public communications (see, Choi (2024)), it is plausible that the public could find generative AI useful for understanding central banks.
Our results provide useful insights into how well AI models do at deciphering FOMC communications and interpreting textual information focused on complex economic and financial market topics.
Establishing Ground Truth
The specific task we used to assess the performance of 11 common generative AI Models involved reading sentences drawn from the text of published FOMC minutes and assigning them to one or more topic categories. An important first step in this approach was establishing a set of 'true' category assignments that generative AI models could be evaluated against. To do this, we constructed an original dataset of sentences from published FOMC meeting minutes from 2010 forward.
Starting from the published html files that contain the meeting minutes, we extracted full paragraphs of text from each meeting. We then separated the paragraphs into individual sentences using searches for stop variables.1 At this stage of the process, we also filtered out sentences from sections related to administration or governance, such as the roll call or annual organizational matters.2
From the resulting corpus of roughly 5,100 sentences, we selected a sample of 20 percent that we manually tagged with one or more of seven topic categories. The categories encompass the broad topics that are routinely addressed by FOMC participants in their prepared remarks and subsequent discussions; examples of sentences assigned to the different categories are shown in Table 1.3 We defined the topic categories based on our extensive readings of meeting minutes and other FOMC communications, as well as our own experience drafting the minutes. Once tagged, this unified dataset of sentences and their judgmentally-assigned topic categories served as our measure of ground truth.
Table 1. Example Categorization of Sentences
| Topic Category | Example Sentence |
|---|---|
| Real Activity | Capacity utilization in manufacturing rose further, to a level noticeably above its trough in June, but remained well below its longer-run average. |
| Labor Markets | Private nonfarm employment rose in September but at a slower pace than in the previous month, while total government employment increased at a solid rate. |
| Inflation | Inflation continued to run below the committee's longer-run objective, apart from fluctuations that largely reflected changes in energy prices, and participants generally saw it as moving back gradually to 2 percent in the medium term. |
| Financial Stability | Two others emphasized the importance of bolstering the resilience of money market funds against disorderly outflows. |
| Financial Developments | Measures of equity market volatility declined over subsequent weeks but remained above levels that prevailed earlier in the year, and stock prices finished lower, on net, over the intermeeting period. |
| Fed Funds Rate | Most survey respondents had a modal expectation that a July rate hike would be the last of this tightening cycle, although most respondents also perceived that additional monetary policy tightening after the July FOMC meeting was possible. |
| Balance Sheet | Survey results indicated that market participants saw a change in the FOMC's policy of reinvesting principal payments on its securities holdings as most likely to be announced in late 2017 or the first half of 2018. |
Putting the Models to Work
We then asked a number of popular generative AI models to make the same topic category assignments to the sentences in our sample. We provided the seven pre-defined categories, and we gave the models some additional context by including one sentence before and after the target sentence. Using an API, we fed sentence triplets through the models iteratively based on a single prompt.
Crafting a prompt for the models that would produce the desired result was an iterative process. In our initial attempts, the models committed input-conflicting hallucinations for some target sentences, returning category assignments that were not among the seven that we had pre-identified in the prompt. Some examples of these errant categories were "Trade," "Credit and Lending," and "Open Market Operations." Other sentences were not assigned to any category, but in these cases the lack of economic content was reasonable, e.g. "The Chairman suggested that the Committee would likely resume a discussion of operating frameworks in the fall."
We ultimately settled on the following prompt:
"You are a macroeconomist who is part of an experiment. Given the previous, TARGET, and next sentence (three sentences in total), classify only the TARGET sentence with ONLY one or more of the following categories, and NOTHING else: Real Activity, Labor Market, Inflation, Financial Stability, Fed Funds Rate, Balance Sheet, and Financial Developments. Provide all the categories that you are certain the sentence belongs to.
Follow this format:
Categories: (List only your categories chosen here separated by commas, do NOT number them, do not say anything other than the categories chosen)"
With this approach, we generated a set of topic category assignments for each of the seven models that we tested. We then constructed performance metrics by comparing the model-assigned topic categories with the true topic categories that we had assigned manually. For each model, we calculated the F1-score, a commonly-used metric that takes on the values in the interval [0,1] and captures performance in terms of precision as well as recall; see, for example, Dell (forthcoming).
We also experimented with an alternative approach to gathering topic classifications from the models. The task of identifying the topic category or categories for each target sentence was the same; but rather than submitting prompts separately for each previous/target/next sentence combination, we tried feeding two of the models 'chunks' of up to 100 sentences at a time.
Model Performance
Table 2 illustrates each category's F1-scores for the 11 different models in our evaluation set.
Table 2. Model F1 Score Comparisons
| Model | Average scores | Average Labor Market + Inflation | Real Activity | Labor Market | Inflation | Financial Stability | Fed funds rate | Balance Sheet | Financial Developments |
|---|---|---|---|---|---|---|---|---|---|
| Anthropic.claude-3-5-sonnet-20240620-v1 | 0.89 | 0.91 | 0.84 | 0.90 | 0.91 | 0.86 | 0.95 | 0.97 | 0.82 |
| Cohere.command-r-v1 | 0.85 | 0.90 | 0.87 | 0.89 | 0.90 | 0.69 | 0.92 | 0.95 | 0.74 |
| Cohere.command-r-plus-v1 | 0.89 | 0.90 | 0.83 | 0.91 | 0.89 | 0.81 | 0.95 | 0.96 | 0.85 |
| Meta.llama3-1-70b-instruct-v1 | 0.91 | 0.91 | 0.90 | 0.90 | 0.92 | 0.88 | 0.95 | 0.96 | 0.85 |
| Meta.llama3-1-405b-instruct-v1 | 0.91 | 0.90 | 0.91 | 0.90 | 0.90 | 0.87 | 0.95 | 0.96 | 0.84 |
| Mistral.mistral-7b-instruct-v0.2 | 0.88 | 0.84 | 0.86 | 0.81 | 0.87 | 0.93 | 0.94 | 0.95 | 0.80 |
| Mistral.mixtral-8x7b-instruct-v0.1 | 0.85 | 0.84 | 0.79 | 0.83 | 0.85 | 0.78 | 0.95 | 0.96 | 0.81 |
| Meta.llama2-70b-chat-v1 | 0.80 | 0.88 | 0.47 | 0.85 | 0.90 | 0.67 | 0.94 | 0.93 | 0.80 |
| Gemini-1.5-pro | 0.93 | 0.92 | 0.92 | 0.92 | 0.92 | 0.95 | 0.96 | 0.96 | 0.90 |
| Gpt-4o-mini | 0.82 | 0.80 | 0.78 | 0.81 | 0.79 | 0.85 | 0.90 | 0.93 | 0.71 |
| Gpt-4o | 0.92 | 0.93 | 0.90 | 0.94 | 0.93 | 0.94 | 0.96 | 0.96 | 0.83 |
| Gpt-4o (chunking) | 0.95 | 0.96 | 0.94 | 0.96 | 0.96 | 0.97 | 0.96 | 0.97 | 0.89 |
| Anthropic.claude-3-5-sonnet-20240620-v1 (chunking) | 0.94 | 0.96 | 0.92 | 0.96 | 0.96 | 0.97 | 0.96 | 0.97 | 0.87 |
Across the seven categories, the generative AI models we tested all produced average F1-scores between 0.80 and 0.93 for our assigned task. We were especially struck by how well the models performed despite the fact that we employed them off-the-shelf with no domain-specific fine-tuning, such as the pre-trained, finance-domain FinBERT model developed by Huang, Wang and Yang (2023). As a comparison, a fine-tuned version of the FinBERT model used by Fischer et al (2023) achieved an average F1‑score of 0.83 percent across categories, among the low end of performance seen by the models in our study.
Among the different topic categories, the models we evaluated were relatively successful at identifying Balance Sheet and Fed Funds Rate sentences, with scores consistently ranging between 0.93 and 0.97. Identifying sentences focused on Financial Developments seemed to be the most challenging task for most models (0.71 to 0.90 range). The Financial Stability category also showed a relatively high variation in performance between the models, ranging from a low of 0.67 for Llama2 to a high of 0.94 for Gemini-1.5-pro.
As shown in the memo lines of Table 1, the alternative 'chunking' approach described earlier resulted in a notable improvement in the models' ability to identify topics. Specifically, the average F1‑score for Claude-3.5 improved from 0.89 to 0.94 when using the chunking approach, and the average F1‑score for GPT-4o improved from 0.92 to an impressive 0.95. Our hypothesis is that the improved performance of the chunking approach owes to the larger information set provided to the models relative to the baseline approach with sentence triplets.
Variation in the performance of different models was loosely correlated with their release dates. To illustrate this pattern, Figure 1 depicts the month and year of release for each of the models we evaluated on the x-axis and their average F1-score on the y-axis. We see notable improvements in the performance of models released in more recent months. Focusing on the generative AI models by Meta in our evaluation set, we see that average F1-scores between Llama2 and Llama3 versions improved markedly, from 0.80 to 0.91 percent. However, that is not to say that newer releases always dominate; indeed, as shown by the chunking approach to prompts described earlier, modest changes in the methods used to interact with generative AI models can lead to substantial differences in the outputs and the models' comparative performance.
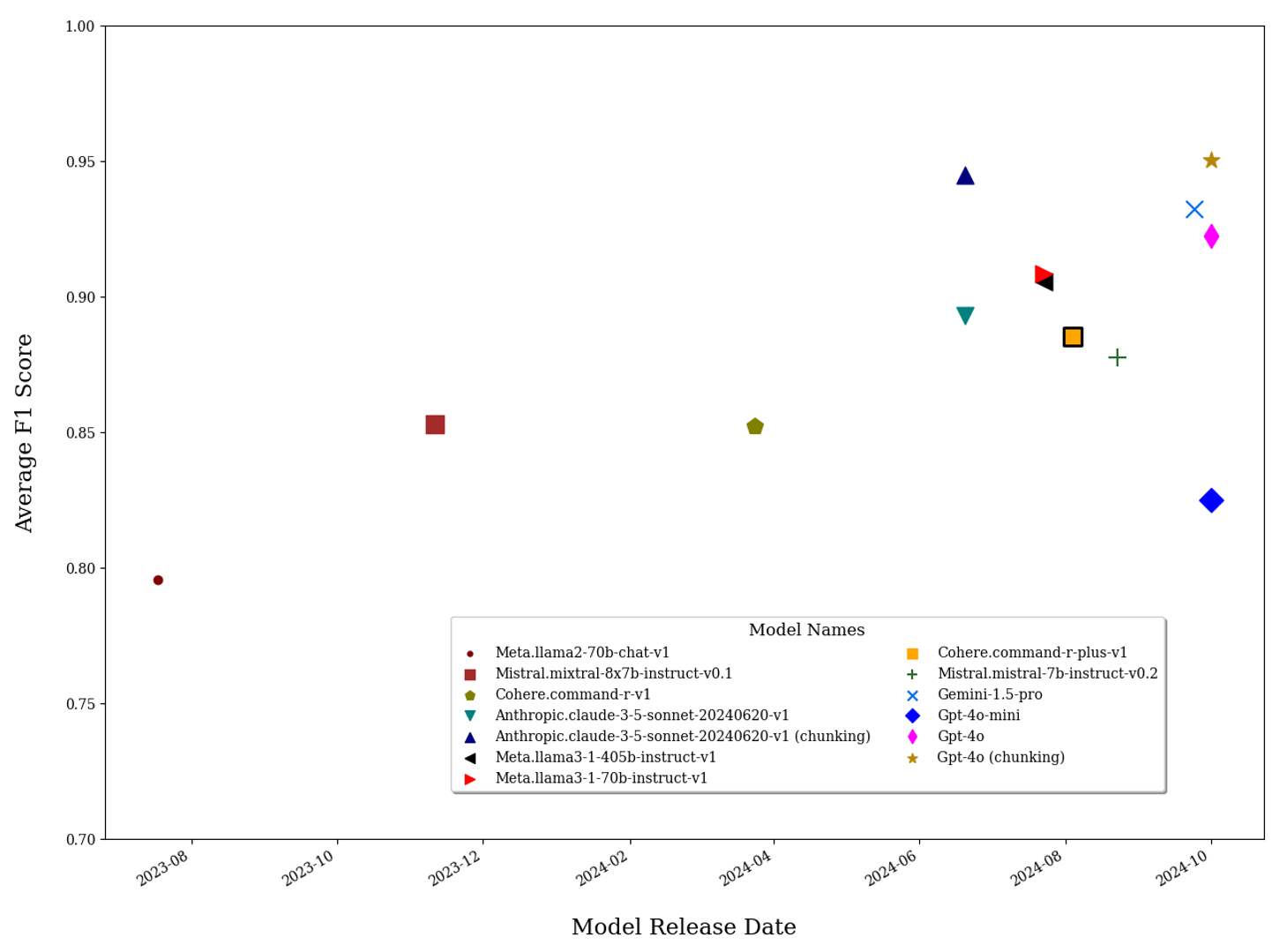
Observing the Content of FOMC Meeting Discussions Over Time
Armed with the best-performing generative AI model in our evaluation set, GPT4-o, we then applied the same sentence-by-sentence approach iteratively to assign topic categories to the full corpus of around 25,000 sentences from the FOMC meeting minutes published between January 2010 and June 2024. The four panels of Figure 2 illustrate the results of this exercise, with separate lines showing the percent of sentences at each meeting that fell within a given topic.4 These model-generated topic distributions offer us a new lens for viewing the content of FOMC meeting discussions and how they have evolved over time.
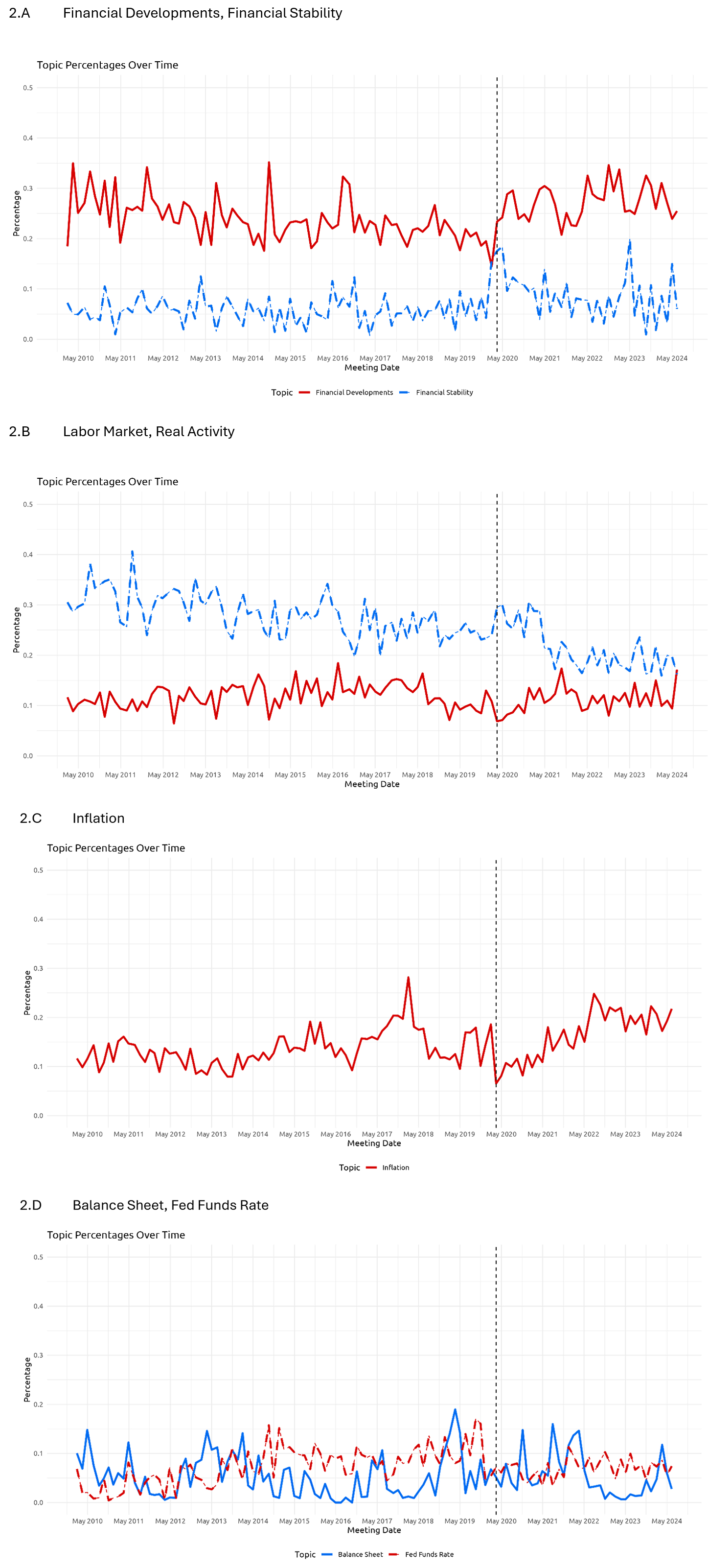
Note: Vertical dashed lines refer to the date of the unscheduled FOMC meeting held on March 15, 2020, near the onset of the global pandemic recession.
Topics shift in prominence over time, perhaps reflecting changing economic priorities and concerns of FOMC participants during their deliberations. We see an increase over the sample in the proportion of sentences relating to Financial Developments and Financial Stability (panel 2.A). Discussions of financial topics also show noticeable spikes at the emergency FOMC meeting in March 2020 early in the COVID pandemic, and again in March 2023 amid the stresses in the banking sector and the failure of Silicon Valley and Signature banks.
By contrast, the Figures show a modest but steady decline in the share of sentences on Real Activity and Labor Markets (panel 2.B) over the 2010-2024 time period. These concerns increase in prominence during the pandemic recession but then taper off quickly, a pattern broadly consistent with the rapid post-pandemic recovery in activity and employment relative to previous economic downturns.
Meanwhile, the focus on inflation in FOMC meetings (panel 2.C) appears to evolve more dramatically. In particular, in the latter half of the 2010s, a period characterized by persistently low inflation and a strong labor market, the prevalence of inflation discussions rose markedly. The visible spike in the inflation series in early 2018 was the result of a special discussion session at the January FOMC meeting dedicated entirely to inflation (see the January 2018 transcripts and background material). Early in the pandemic inflation concerns were quiescent, but—according to the minutes—the focus of discussions visibly shifted toward inflation in 2021, increased further through early 2023, and along with Financial Developments, has remained a topic at the forefront of FOMC discussions to date.
Finally, as seen in panel 2.D, the discussions around the Fed Funds Rate and Balance Sheet are relatively minimal. FOMC discussions increase their focus on the Fed Funds Rate for brief periods around the liftoff period in 2015-16 and again in the early days of the pandemic recession when the Committee quickly reduced the policy rate back to its effective lower bound. The Balance Sheet category is typically not a major focus of discussion but does gain prevalence at a few distinct points in time, most notably at the end of 2018 when the FOMC discussed its long-run operating framework, which it announced at the January 2019 FOMC meeting.
Discussion
The purpose of this note is to provide an early assessment of how well generative AI models decipher the content of FOMC meeting discussions from the published minutes. By first establishing a dataset of ground truth based on our expert judgment, we were able to evaluate the extent to which different generative AI models correctly classified the focus of meeting discussions from the text. Overall, the models showed great potential, performing our assigned task with a high degree of accuracy and recall.
In future work we plan to investigate the capacity of generative AI models to infer more nuanced aspects of policy discussions from the minutes, such as understanding the most salient risks perceived by FOMC participants or identifying areas of disagreement among meeting participants.
References
Bird, S. a. (2009). Natural language processing with Python: analyzing text with the natural language toolkit. O'Reilly Media, Inc.
Choi, J. (2024, November 12). The frontiers of AI in central bank communications. Retrieved 2024, from www.centralbanking.com: https://www.centralbanking.com/benchmarking/communications/7962632/the-frontiers-of-ai-in-central-bank-communications
Dell, M. (forthcoming). Deep Learning for Economists. Journal of Economic Literature. doi:https://doi.org/10.48550/arXiv.2407.15339
Fischer, E. a. (2023). Fed transparency and policy expectation errors: A text analysis approach. New York: FRB of New York Staff Report. doi:https://doi.org/10.59576/sr.1081
Huang, A. H. (2023). FinBERT: A large language model for extracting information from financial text. Contemporary Accounting Research, 40(2), 806--841. doi:https://doi.org/10.1111/1911-3846.12832
1. Stop variables indicate the end of a sentence – for example, a period followed by space. We also used a common list of abbreviations through the natural language toolkit (NLKT) developed by Bird et al (2009) in order to ignore the periods in abbreviations. Return to text
2. A forthcoming working paper includes a more detailed description of how we assembled and organized the original dataset of FOMC meeting minute sentences and their assigned topic categories. Return to text
3. In a previous study by researchers at the New York Fed (Fischer et al, 2023), the authors used LLMs for text analysis of historical FOMC meeting materials and defined similar (though fewer) categories independent of our effort. Return to text
4. The percentages sum to more than 100 percent because some sentences are assigned to more than one category. Return to text
Dunn, Wendy, Ellen E. Meade, Nitish Ranjan Sinha, and Raakin Kabir (2024). "Using Generative AI Models to Understand FOMC Monetary Policy Discussions," FEDS Notes. Washington: Board of Governors of the Federal Reserve System, December 06, 2024, https://doi.org/10.17016/2380-7172.3678.
Disclaimer: FEDS Notes are articles in which Board staff offer their own views and present analysis on a range of topics in economics and finance. These articles are shorter and less technically oriented than FEDS Working Papers and IFDP papers.